1. Introduction
The Internet has become increasingly social due to the rise of Web 2.0. There are many different social features implemented in websites, (mobile) applications, and on Internet platforms. These features enable us to continuously communicate with – but also keep track of – our friends, distant relatives, or total strangers. However, the productivity changes remain unclear (Dabbish et al. 2012; Langlois 2011, 2009).
GitHub’s mission to make coding social should be understood as an effort to make collaboration technical. As a digital platform, GitHub1 is engineering and manipulating the way we connect (cf. van Dijck 2013); collaboration, reputation, innovation, sharing, community, and so on, become coded concepts defined by the owners of the platform. Software developers use GitHub to collaboratively organise the development of projects that span over temporal and spatial distance. With over three million users,2 GitHub has grown into the largest web-based code-hosting platform. It is important that we should think about how we can understand the platforms we build, for they become constitutive of the way we think, interact, and relate to each other. GitHub determines not only how and what we learn, but also who we learn with, our understanding of innovation, or the way we coordinate our efforts towards a wide variety of shared goals.
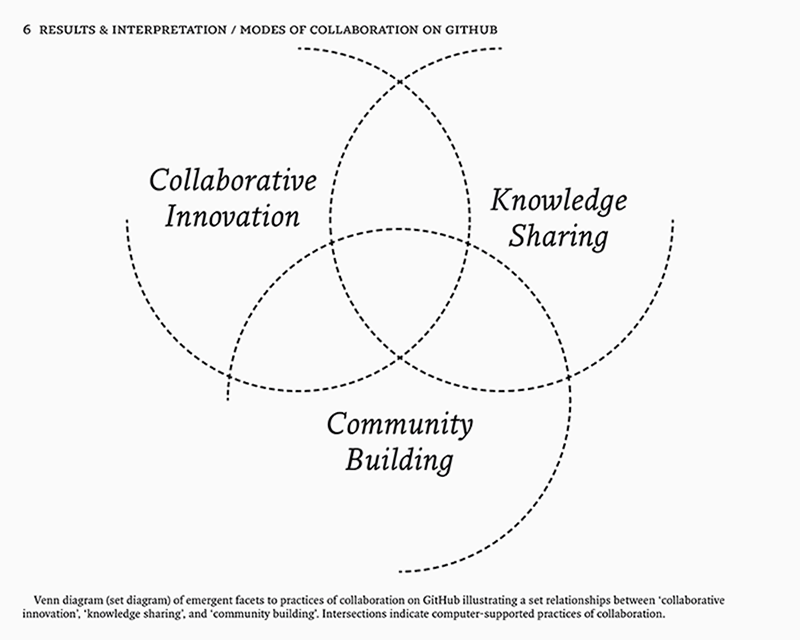
The approaches now known as software studies and platform studies aim to describe these software platforms and mechanisms and try to make sense of them (Fuller 2008; Bogost and Montfort 2009). The perspective of platform technicity in particular seems to offer a fertile ground to look into the many ways technical rationalities and infrastructures structure and govern the relations between humans and their technical supports (Bucher 2012; Niederer and van Dijck 2010; Crogan and Kennedy 2009). By addressing the following research question, we may advance our understanding of how specific material arrangements like GitHub can enable, capture and augment computer-supported collaborative innovation, knowledge building and community building: in what way is the technicity of collaboration on GitHub co-constitutive of computer-supported collaborative innovation, knowledge sharing, and community building? This question is approached from three different, but intertwined angles. Git, the main underlying infrastructure, is first approached as a technical foundation or infrastructure supporting further layers of the GitHub platform that are discussed in the subsequent sections. Second, the practice of collaboration on GitHub is considered by looking into the way specific features augment or serve to deal with particular strengths and shortcomings of Git, and what that means for collaboration. Third, I discuss some of the distinctive features on GitHub that produce activity awareness by constituting an information transparent environment.
2. Theoretical Framework
The following is a reflection on the broader conceptual frameworks to which this research contributes. With a main focus on understanding the “technicity” (Crogan and Kennedy 2009)3 of collaboration on GitHub, this research is situated somewhere between the academic disciplines of software studies (Fuller 2008),4 platform studies (Bogost and Montfort 2009),5 and digital methods (Rogers 2012, 2009).6 As such, it is grounded in the philosophical tradition of the digital humanities (Berry 2011, 2012).
As defined by Ian Bogost and Nick Montfort, a platform is: “a computing system of any sort upon which further computing development can be done. It can be implemented entirely in hardware, entirely in software (which runs on any of several hardware platforms), or in some combination of the two” (2009). In their view, a platform often contains other platforms, which is a useful way of thinking about software and platforms from a perspective of technicity analysis. The notion of technicity embodies the key approach of this research to understand the techno-social structure of GitHub. Bucher (2012, 4), and Crogan and Kinsley (2012, 22) both take this concept to be “the inherent, coconstitutive milieu of relations between the human and their technical supports, agents, supplements (never simply their ‘objects’)” (Crogan and Kennedy 2009, 109). Technicity is why software can be productive (i.e. “do work” in the world), why it can make things happen. It marries the technical object to the context of which it is part, which is to say that they become mutually constitutive.7 The question of what collaboration is then becomes how collaboration becomes.8 In many ways, this approach answers to Geoffrey C. Bowker and Susan Leigh Star’s call to start taking infrastructures seriously (1999). Infrastructure is defined as a relational concept, embedded in other structures, social arrangements, and technologies (35).9 Technicity takes this understanding of infrastructures to the domain of software and platform studies by focusing on the constitutive relations between the technical infrastructures and – in a broad sense – specified human actions. With this conceptual and structural frame in mind, I explore the implications on computer-supported collaborative innovation, knowledge sharing, and community building.
These perspectives are all still in their infancy and in addition to their short existence, the research on software and digital platforms also seems disproportionate to the increasingly pervasive role they play in our (everyday) lives. It has become difficult to even imagine a world without software. This is not just a consequence of being so dependent on automated support mechanisms for our regular activities, but more importantly of a lack of understanding of “the stuff of software” (Fuller 2008) in spite of this dependence. As a result, this research draws heavily from a variety of other disciplines such as software engineering, artificial intelligence, organisation studies and other categories of computer and information science. This way we may be able to bridge some of the gaps between technical engineering, development, implementation and maintenance on the one hand, and thorough analytical and critical understanding of their implications on the other.
2.1. Distributed Computer Systems
GitHub was founded in April 200810 and uses Git as system for version control. Git follows the logic of a distributed computer system, so it is necessary to consider this in terms of implications for any additional layers of software and interaction. Previous research and development of distributed computer systems and networks has resulted in broad adoption and implementation (Milenkovic 2003).11 Peer-to-peer networks and file-sharing practices have emerged and caused scholars to rethink these systems and networks not only on the level of technical infrastructure, but also as models of cultural production, cooperation and distribution (Bauwens 2005).12 A recent example of such a discussion centred on version control systems. Centralised version control systems (CVCS) such as Subversion are gradually being replaced by distributed version control systems (DVCS) such as Git, Mercurial, or Bazaar, for they are much more flexible and able to scale in administration, size and spatial distance (Tanenbaum and van Steen 2007).13 This spawned discussion on the pros and cons of centralised versus distributed models of version control, how the actual work process is transformed because of this, and specific issues that follow from migrating between two such systems (de Alwis and Silito 2009).
2.2. Computer-Supported Cooperative Work
Computer-Supported Cooperative Work (CSCW) repeatedly surfaces as the key site of debate for computer-supported group work and its issues especially before the rise of the Web 2.0 era of platforms and peer-production. CSCW started as an interdisciplinary effort to shed light on supporting group activity (Grudin 1994, 19–20).14 Irene Greif and Paul M. Cashman first coined the term in a workshop (1984) on the role that technology could play in human group work (Grudin 1994), and was later defined by Peter H. Carstensen and Kjeld Schmidt to describe “how collaborative activities and their coordination can be supported by means of computer systems” (1999, qtd. in Itoh 2003, 620). Most of the previous research on CSCW that is relevant here stems from computer science in the eighties and nineties (Grudin 1988),15 and now seems to continue in the slightly different context of social computing implementations.
Social computing implementations can deal with some specific issues that could not be resolved before, even though these had been identified at the time (Schmidt 2002). These are issues of coordination such as lack of awareness and workspace transparency that follow from the move from local (i.e. with physical proximity to other members) to networked (i.e. where members are physically scattered) group working environments (Gutwin et al. 1996; Gutwin and Greenberg 2002; Pinelle et al. 2003).16 This has caused a general shift in development style of open source software from the hierarchical “cathedral” model to something that resembles a “bazaar” (Raymond 1998), resulting in different categories of collaboration such as episodic and continuous collaboration (Rigby et al. 2010; section 4.3.) and the emergence of the endless beta stage of development to harness this collective intelligence (O’Reilly 2005). In this “neodemocratic” environment, different values are important that emphasise commitment to issues rather than information secrecy (Dean 2003). As a web-based code-hosting platform for social coding, GitHub has a very particular understanding of publicness. Ownership and influence become concerns of access and permission protocols17 (section 5.1.), causing a reconfiguration of the public and private (section 5.1.).
2.3. Social Computing in Open Source Software Development
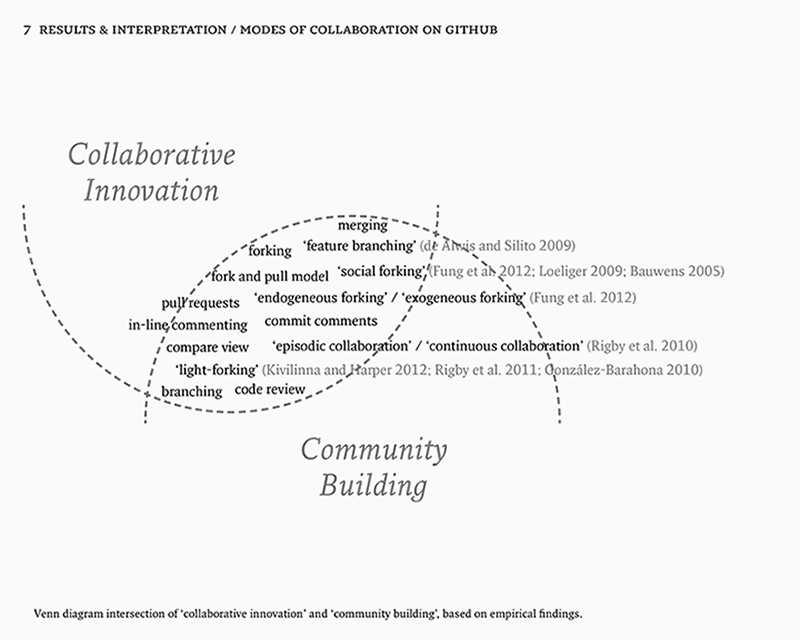
Social computing has also been explored specifically in open source software development (Şahin et al. 2013; Dabbish et al. 2012; Begel et al. 2010; Fihin 2008). It is not just about notification systems, but also about how specific features actually become social. Social forking (Fung et al. 2012), “light-forks” (González-Barahona 2008; Rigby 2010) and merging make particular interesting cases in that they show how code and community are attached to each other (section 4.3., 5.3). Code is a social object among developers (Dodge and Kitchin 2011), emphasising the importance of “social learning” (Bandura 1977), and “code literacy” (Berry 2011; Hayles 2004) as a required skill to participate both as a developer and as a critic (section 5.2.). The key consequence of this is the implementation of an information-transparant environment that allows for activity awareness to both produce and uphold effective collaborations. The concepts of “capture” (Agre [1994] 2003) and “social inferences” (Dabbish et al. 2012) are useful as frameworks to make sense of this environment (section 6.1., 6.2).
Research on open source software (OSS) development (Raymond 1998)18 has only recently started to embrace the large amounts of data that enables researchers to empirically study software development at large scales and across communities (Mockus 2009). For example, by using data from user profiles, repository metadata from GitHub, Heller et al. (2011) were able to visualise collaboration and influence between developers on a map and identify patterns that would otherwise have remained obscured. This kind of empirical research relies entirely on the quality and size of the public datasets with data on profiles, activity, code, and repositories. The interconnections between the global and local (both geographically and as variables on the platform) need to be considered as well. David Redmiles, for example, explicitly chose to use the term “global software development” to distinguish it from local forms of software development (Redmiles et al. 2007). This should be considered both as a consequence scale-increases (Wilson 1996)19 and of migration across communities such as when code assemblages occur (Fung et al. 2012; section 4.2., 4.3).
3. Research Methodology
In order to address the research question, it needs to be separated into two parts. The first concerns understanding the platform technicity of GitHub, and the second part requires this understanding to make sense of collaboration in terms of innovation, knowledge sharing, and community building. To answer this twofold question, a methodology has been deployed that is similar to those of Bucher (2012), Niederer and van Dijck (2010), and Dabbish et al. (2012). Their research is similar in that Dabbish et al. develop an understanding of how users infer information and meaning from particular functions on GitHub. Bucher, Niederer and van Dijck, on the other hand, used their empirical findings to open up space for a critical perspective on Wikipedia’s standards. It is this particular intention in conducting empirical research that I believe is important.
The first part of the research question is descriptive, and is engaged as an empirical question. The aim is to develop and describe a functional and structural overview of GitHub to understand which of its many features are important to the research question, and how these features relate to each other. Functional description, in this case, means separating the elements and classifying them based on what they do (in the broadest sense). Structural description, on the other hand, focuses on navigational structure and content organisation. The structural becomes relevant when considering features in relation to one another.
To engage with this kind of description, one needs to explore and document features and how these are implemented into the system. The empirical corpus, then, consists of descriptions and discussions on the various implemented systems from blogs, previous research, and observation. In this regard, documents on GitHub are often useful. The GitHub team keeps their developer blogs20 public and up-to-date; GitHub’s help subdomain21 contains extensive description; legal documents such as terms of service,22 privacy and security statements23 are all publicly available; an analytics subdomain24 is dedicated solely to the platform’s status history; and user accounts are publicly accessible, including their detailed data such as activity statistics, project pages, repositories and open source code of the projects they have worked on.25 Description alone, however, will not suffice to really understand software. The second part of the research question therefore aims to extend this empirical foundation in order to make sense of the implications of this particular technicity of collaboration on three connected aspects. These aspects are computer-supported collaborative innovation, knowledge sharing, and community building. This means providing what Clifford Geertz and others26 have called “thick descriptions” (Geertz 1973, 3–30, ch. 1; Murdoch 1997, 91–98, ch. 9); describing both an empirical observation, and its broader implications or deeper meaning. This approach criticises “thin descriptions” of cultural ethnographic analysis that only give empirical findings without contextualising them properly.
In line with Bucher’s essay on the technicity of attention, this thesis will not be focusing on describing what collaboration is, nor will it be an exhaustive study of what all the features on GitHub exactly do. Rather, it will show how software has the capacity to produce and instantiate modes or aspects of collaboration, specific to the environment in which it operates (cf. Bucher 2012, 13). In what follows the empirical findings and discussion will therefore repeatedly alternate to develop the central thesis. GitHub as knowledge-based workspace is both an infrastructure that can be used through local applications such as the command line interface or the native application,27 and a web-based platform that you can visit and explore. For the first perspective we may take a closer look at the core infrastructure underlying the platform in order to discuss how computer-supported innovation, knowledge sharing, and community building can result from this foundation. After that section we can then start considering the wide range of features and possibilities that follow from the specific implementation on GitHub. In the final section of the main part this implementation is revisited in the light of activity transparency and awareness on the platform.
4. A System for Distributed Revision Control and Source Code Management
This section will discuss how Git helps producing and instantiating specific modes of collaboration that are specific to the platform. Git is approached here as technical foundation to support functionality that is discussed subsequent sections. First I will describe Git on the level of its distributed VCS architecture, after that I focus on data storage in particular to discuss modes of collaboration.
4.1. Moving From Centralised to Distributed Version Control Systems
Version control systems play an important role in the software development process (Sink 2011; Chacon 2009). As one of the main project management strategies, source and version control is needed keep to track and structure cooperative software development. Brian de Alwis and Jonathan Silito summarise the key differences between centralised and decentralised systems. According to the authors, decentralised VCSs are succeeding centralised VCSs as the next generation of version control (2009, 36).28 Realising that a change at the core of the development process will affect the workflow, de Alwis and Silito summarise some of the differences between these systems and describe the rationales and perceived benefits offered by projects to justify the transition between them. In a centralised VCS “write-access is generally restricted to a set of known developers or committers” (37, original emphasis). As a second characteristic, they write, “modern VCSs support parallel evolution of a repository’s contents through the use of branches”. The developers thus require access in order to contribute and earn this by submitting quality work. This way, the quality of a project can be secured. Branching is often used to split the mainline branch of development from the smaller challenges during the development. This way, challenges of different scales can be stored and developed at the same time, and at a different pace.
Raymond (2008) refers to DVCSs as a third generation of version control systems and started appearing in the late 1990s and early 2000s (Harper and Kivilinna 2012, 3). Decentralised systems do not require a central master repository, because “each checkout is itself a first-class repository in its own right, a copy containing the complete commit history” (de Alwis and Silito 2009, 37). Each developer, then, is essentially contributing to his own copy of the project, rather than to a shared project. Branching and merging are also used differently in development supported by DVCS: “DVCSs maintain sufficient information to support easy branching and easy, repeated merging of branches. The ease of branching has encouraged a practice called feature branches, where every prospective change is done within a branch and then merged into the mainline, rather than being directly developed against the mainline” (37, original emphasis). The fact that repositories in a DVCS store the complete revision control history is particularly interesting. Because of it, they lend themselves very well to distributed and disconnected development (37). For example, remote locations do not need to have a constantly stable network connection with the central repository, and a change or problem in a single, central repository is not as permanent or dangerous anymore. Every repository is effectively also a backup that reduces the risk of data loss or overwrites involved in such disconnected processes. De Alwis and Silito’s research based on the Perl, OpenOffice, Python, and NetBSD open source projects resulted in five anticipated benefits of DVCS over CVCS: “to provide first-class access to all developers … to support atomic changes … simple automatic merging … improved support for experimental changes … [and] support disconnected operation” (38). For programmers working with these systems on a daily basis, the main challenges seemed to be the transition from one workflow to another, and the compatibility and communication issues that come with it (38–39). Because each clone is a copy of the complete project, there are also legal ramifications to consider for these projects. Once a commit is submitted, every connected developer will have a copy as well. It seems, then, that open source software development and DVCS complement each other in interesting ways and are both fundamental layers of the Git infrastructure (section 5.1.).
Gavin Harper and Jissi Kivilinna discuss DVCSs in the context of open source software development, while also drawing comparisons to traditional CVCSs. The main argument they make is that distributed version control is beneficial to open source software development, but that it is contingent upon project requirements and deployed models of governance (1). Just like de Alwis and Silito they note as well that branching and forking make for curious aspects of DVCSs (4), because each clone of the project is at the same time a fork or branch (Fung et al. 2012). However, they also stress that this is not a typical fork, but rather a kind of “light-forking”: “They argue that historical forks where source code of [a] large project is copied under different governance differ significantly from forks whereby a developer makes a small, or insignificant change, ensuring that the core of the project remains unmodified” (Rigby et al. 2011, qtd. in Kivilinna and Harper, 4). DVCSs also stimulate developers to experiment, because any amount of branches can be tested without making permanent changes to a main branch and thereby risking the project development. The result, according to Kivilinna and Harper, is an ad-hoc workflow and interaction between the developers that consists of simple merges and small operations. The use of feature branches may improve the quality-of-code over traditional development iterations. On the level of community, DVCSs also significantly lower the entry barrier for new contributors, for new members to join the development, and for improving learning opportunities for starting programmers. As a result, write-access does not have to be restricted for reasons of quality control anymore (section 5.1.).
4.2. Storage and Source Code Management in Git
At the core of a version control system like Subversion is the repository, which refers to a data structure that organises the data in a central location.29 In Git, this works in a similar, but slightly different way. In Pro Git, Scott Chacon notes that DVCSs have no central location for storage anymore, and this has several implications. First, nearly every operation is local. Which, in turn, determines the three states that files can reside in: they can be committed, modified or staged (6–7). Respectively, these states correspond with the three main sections of a Git project: the Git repository, the working directory and the staging area (7). Because nearly every operation takes place locally, Git becomes an infrastructure for an environment where individual developers work on projects in a highly disconnected, yet cooperative effort. Obviously, this makes it hard to find and develop projects with complete strangers. The GitHub platform, then, is not so much a hub in the technical sense, but rather a social hub to connect with projects or people and that synchronises individual work into cooperative effort. In that sense, GitHub acts as a matching service. Second, Git has what Chacon calls “integrity” (6). He describes this as follows:
Everything in Git is check-summed before it is stored and is then referred to by that checksum. This means it’s impossible to change the contents of any file or directory without Git knowing about it. This functionality is built into Git at the lowest levels and is integral to its philosophy. (6)
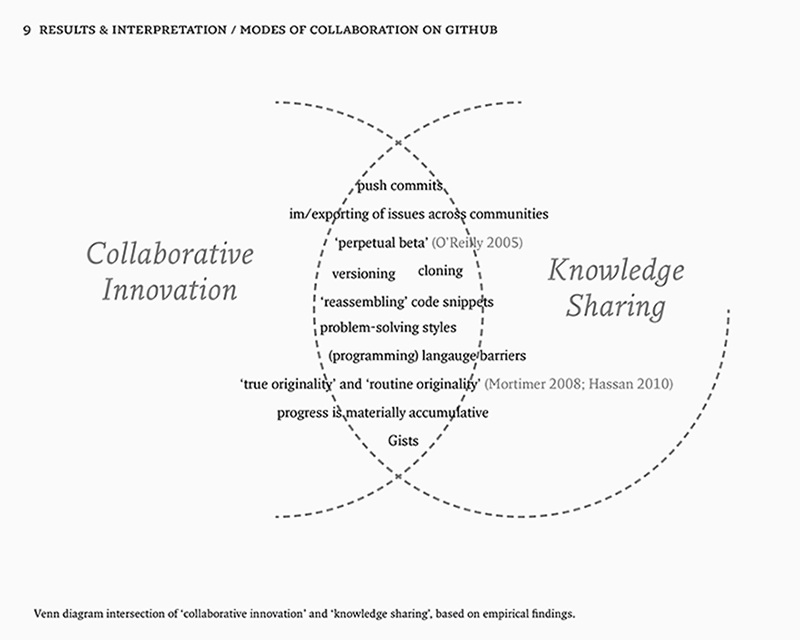
Although this may come across as a technical detail at first, it is essential to understand the branching and merging operations that are so important to collaboration on Git. By integrity, it seems, Chacon points to a philosophical consistency in how Git uses checksums to refer to data in the repository. This referring happens via the index, which organises the data in the repository by pointing to specific parts in it. This way, the repository never has to change, and the index can simply refer to all elements that are required in the working directory. This is what the checksum refers to; the unique sum of hash values (in this case of the required elements for a specific point in the development). Branching or merging simply results in a different checksum that can still refer to the same elements in the repository. The repository, then, is a collection of snapshots that can constantly be reused to form new code assemblages. These assemblages occur when different project networks (not just code, but also the associated community and organisation) converge and become integral to one another (cf. Dodge and Kitchin 2011, 7). If we consider creativity and originality here, this model prefers a model of innovation that is based on combining and reassembling pieces of existing content. This enables “remixing” from small snippets of code to complete features. Third, Git generally only adds data. As long as you work locally in the working directory, you are vulnerable to data loss. But as soon as you commit the files, it is very difficult to lose or remove data (6). A typical workflow in Git starts with modifying files in the working directory, followed by staging them in the form of snapshots, followed by pushing a commit, which permanently stores the staged files in the Git repository (7). Contributions are hard to “forget”, which favors development of software that embodies the logic of a future based on past data.30 Progress is not so much linear as it is materially accumulative. This idea of creating something based on repurposing existing pieces of code supports distributed modes of collaboration that seek to create assemblages. It also raises critical questions whether we should remember everything just because we can.31
Another major aspect to storage in a DVCS is versioning. Instead of saving changes between files as they change, Git just stores snapshots (Chacon, 5). This has important consequences for the notion of ontology and managing change. Timothy Redmond et al. presented some basic requirements and initial design of a system that manages change to an OWL (Web Ontology Language) ontology in a multi-editor environment (1). Among the requirements they identified for that system is “concurrent editing” (2), which deals with conflicting changes to a project. The interesting thing, however, is that Git doesn't seem to really deal with conflicting changes. Instead of forcing a user to choose between continuing either this version or that version, it just saves them both, suspending the project direction. The outcome is not many dead projects, because projects are sometimes forked, or issues are revisited in discussions months later.32 This tells us that decisions are made and coordinated in a different way. Another requirement the authors identified was “complete change tracking” (2). While discussing it, they point to the need to see the history and evolution of an ontology. Although this certainly seems true, the idea of ontologies is itself problematic. As critically discussed by Florian Cramer, ontologies are both useful and problematic: “they reference what computers, as purely syntactical machines, cannot process, and which can't be mapped into computer data structures except in subjective, diverse, culturally controversial and folksonomic ways” (2007). If that is true, then the idea of managing change in an ontology might be problematic as well. Certainly there are different interpretations of what progress means, and Git only captures one of these interpretations. Git’s idea of progress or innovation seems to be oriented towards endless revisions that are not necessarily advancing towards a common goal. Instead of creating something new, it is often easier to revise something existing. In terms of workflow, this means that what Ian Mortimer calls “true originality” (Mortimer 2008, 16–17; Hassan 2010, 366) is often overshadowed by “routine originality”.
The specific versioning method has become an important point of critique on Git. As identified by de Alwis and Silito (2009, 39), Koc and Tansel (2011), and Harper and Kivilinna (2012, 7), the absence of an “understandable version numbering system” is one of the main disadvantages of distributed systems and results in a less intuitive experience: “due to the potentially unclear methods of tracking modifications including a hash of the changeset or a globally unique identifier as a means of identifying the current state of a software project” (Koc 2011, qtd. in Harper and Kivilinna 2012, 7). This makes it useful to consider how this dictates traceability and versioning of modifications. Harper and Kivilinna continue to stress this: “In situations where there exists a centralised server containing a single repository, all changes made thus represent the singular state of the software project at a given point in time. However, should this be distributed, there does not exist a single coherent version that can be tracked” (7). Working without a single version could effectively mean losing the sense of progress towards a final version (Figure 4.1). This not only makes it harder to coordinate group work; it also becomes problematic to define states in the development of a project, and makes it a lot harder to recruit developers in the first place. The direction, if there is any, constantly changes. If there is no clear direction behind a project, then why should anyone want to spend time and effort on a small or larger project? To answer that, it is necessary to reframe what makes a project in relation to collaboration.
4.3. Nested Assemblages of Code
As far as the system is concerned, projects do not exist. There are only repositories consisting of files and directories, records of changes, the commit objects, and the heads that refer to these objects. To create a new project, one can either create a new repository with “$ git init” and add files with “$ git add”, or clone an existing repository with “$ git clone [URL]”. Each repository has a unique resource identifier (the URL), and if the project is on GitHub it has a project page with an overview of activity, issues, and files, including a “README.md” (markdown) file that contains an actual project description (Figure 4.2). For developers, projects may span over multiple repositories.33 Each fork or clone results in a new repository, but may still be part of the same project. A new feature or a version of the software that is compatible with a certain platform is often created as a fork or branch of the main project.34 Another example is the Android project, which started as a fork of Linux and has recently been re-merged with the mainline.35 As separate projects, different distributions developed different solutions to certain issues. This lead to many heated words over what the right solution was to specific issues, or just what thing Android actually was in relation to Linux. What this demonstrates is the “torquing” (Bowker and Star 1999, 190) that happens when different conflicting classification schemes are being merged. It’s not just about merging code; communities, organisations, and ideas are merged as well.
To describe the work-style where each repository evolves independently of the other, Peter Rigby et al. have proposed the notion of “episodic collaboration” (2010). In their words, “[t]eams and individuals work independently and in parallel, and then merge later, leveraging git’s fast and easy merging” (3). For another work-style where repositories are shared they introduced the notion of “continuous collaboration”, which they describe as “[t]he scheduler, and the … networking teams can coordinate work, dividing labor and sharing contributions on a common sub-task via their shared repository”. Both are useful models to think about collaboration in relation to Git. Episodic collaboration, for example, accounts for the modularity of code edits that are committed without any knowledge about the endeavours behind a project; committing just for the sake of committing. This can still be very productive, a bit like dialogue or what Lev Manovich termed “media conversations”. That is, commits become tokens to initiate or maintain a conversation (2009, 326). On the other hand, continuous collaboration becomes useful when thinking about teamwork and labour division among developers. Maybe the former cannot be counted on, but might be useful for solving difficult issues or initiating new directions, while the latter can be planned and coordinated much more efficiently.36
5. The Practice of Collaboration in an Open Source Software Repository
In the previous section I have shown that the specificities of Git has resulted in ad-hoc workflows, and a particular understanding of projects as nested code assemblages that also contain communities and organisations which are relative to that code. This resulted in two general modes of collaboration that coexist in the same space. It was necessary to discuss Git because it is one of the ways that GitHub is used as infrastructure, but also because it forms the foundation for GitHub as a web-based platform. Continuing this exploration we can now start addressing GitHub. From here on, I look at GitHub as a socio-technical construct to understand how certain features augment or serve to deal with particular strengths and shortcomings of Git, and relate this to the implications for collaboration.
5.1. A Reconfiguration of the Public and the Private
One of the things that the open source philosophy promotes is free distribution and access to source code and implementation details (Stallman 1985). This seems opposite to the notion of ownership. N. Katherine Hayles argues that “[t]he shift of emphasis from ownership to access is another manifestation of the underlying transition from presence/absence to pattern/randomness” (1993, 84). Hayles wrote this in the context of what she called the disembodiment of information. When software is not a package deal, but constantly in development, it also loses some of its materiality. The question of accessibility becomes a question of permissions that govern levels of availability and influence. The Help pages on this topic explain these permission protocols: “user accounts and organisation accounts have different permissions models for the repositories owned by the account”.37 User accounts have two permission levels; the account owner has full control of the account and the private repositories owned by the user. Collaborators have push/pull access. As there are only two permission levels here, there is not much room for protocological hierarchy in the development. Hierarchy on GitHub follows from a different set of socio-technical factors (section 6.1.). Organisation accounts have more levels of access to organise account teams. A distinction is made between owners, admin teams, push teams, and all teams (pull, push, admin and owners). Axes of permission (parameters) are repository access, team access and access to organisation account settings. To summarise the permissions briefly: the owner can do everything; the admin teams cannot access account settings and cannot add or remove users to the repositories they admin; push teams can push (i.e. write) to the repositories, but cannot access account settings and can only view team members and owners; and all teams can pull (i.e. read) from the repositories, fork, send requests, open issues, edit or delete commits and comments, and edit wikis. In this environment, hierarchy is about trusting someone with the permission to have influence. Ownership, in other words, is still there, but is layered into levels and assumes a different form. The owner is not so much a possessor of property as a maintainer or coordinator of a process. Ownership and direction are intertwined, and the owner is also the lead developer.38 This is because at the other end, the default right of new users is still quite large. Any user can suggest a new direction and fork the complete project, which makes that user the owner of the exact same data, but not of the same community supporting it.
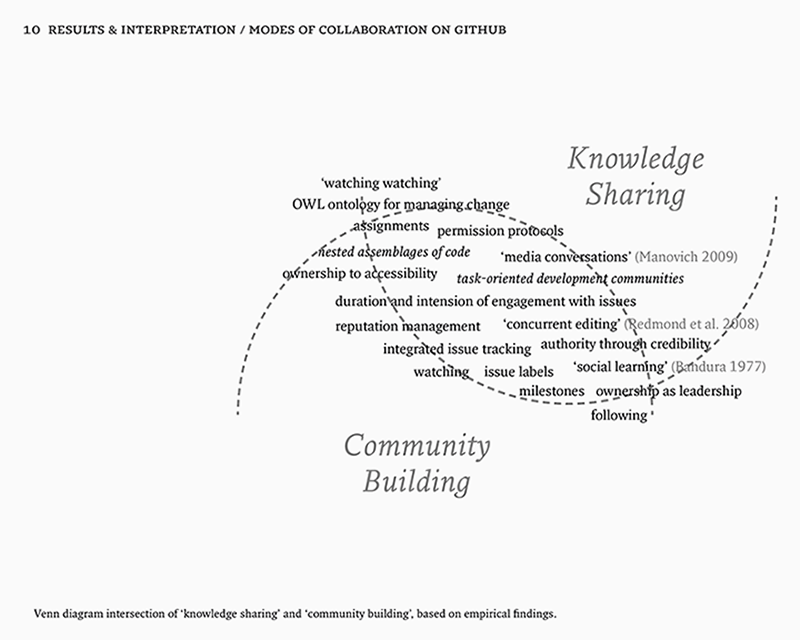
But then how is consensus reached among the developers? Hayles observed that a shift of emphasis from ownership to access also results in a reconfiguration of the distinction between private and public (Hayles 1993, 84). GitHub offers private and public repositories, and by paying a monthly amount of money, developers can keep their projects private39. By default, a free repository is public. In this particular dichotomy between private and public, transparency of information is less scarce than information secrecy. There is an inherent risk of privacy, and extra efforts are required in the form of security and general cautiousness.40 In the public section of the platform there is a different political architecture, one that seems to be more specific to the Web. Jodi Dean proposed “neodemocracies” as an alternative to the public sphere (2003). Instead of the nation, she considers the Web as “zero-institution” (i.e. as empty signifier that signifies the presence of meaning) where consensus is replaced by contestation; actors by issues; procedures by networked conflict, inclusivity by duration, equality by hegemony, transparency by decisiveness, and rationality by credibility (108). This “communicative capitalism” is a useful step towards thinking about publicness on platforms. In this model, it is key to focus on issues, not actors as vehicles (110). Inclusiveness is not scarce anymore, because everyone has a certain degree of access. What matters is duration, or the prioritization of interest and engagement with an issue, rather than inclusion for its own sake (109). Decisiveness replaces transparency, because power is not hidden and secret anymore, and what matters is decisive action. When communities gravitate towards issues or projects on GitHub, it is not about rational debate. Consensus is not reached through reasoning, but through quality and credibility behind the commit, which increases reputation. Credibility replaces rationality. This perspective calls for a better understanding of GitHub as an environment where commitment to issues, social status, and reputation management matter. This makes issue-oriented coordination (section 5.2.), task-oriented development (section 5.3.), and activity capturing (section 6.) sites of further inquiry.
5.2. Issue-Oriented Coordination
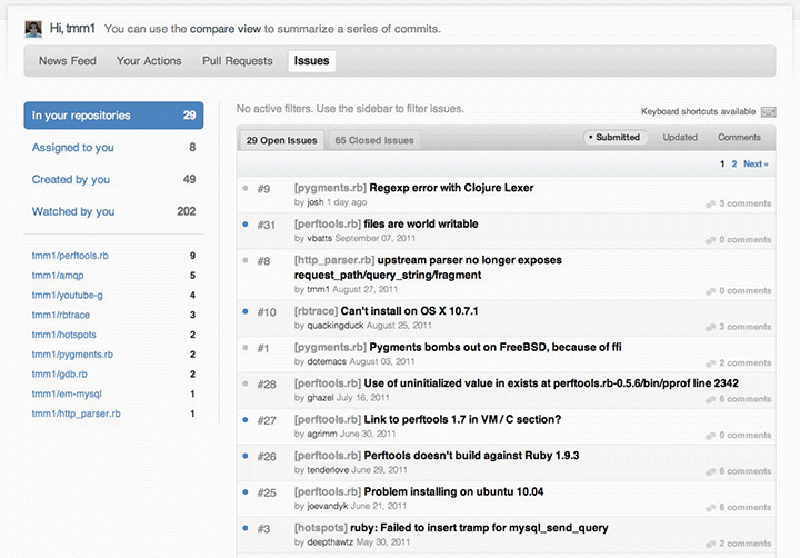
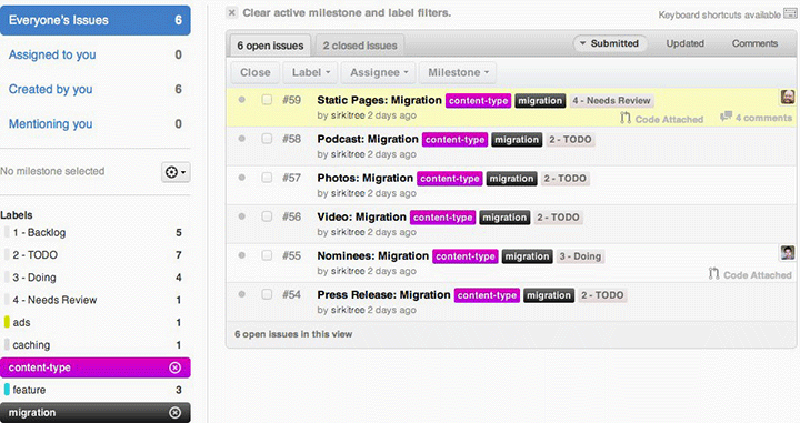
On GitHub, every user can create and view issues on public repositories.41 Introduced in April 200942, an integrated issue tracking system supposedly lets you deal with issues “just like you deal with email (fast, JavaScript interface),”43 and allows users to categorise, apply labels to these issues or assign them to someone. Additionally, users can also vote on issues that you want to see tackled, and search or filter for them specifically. In April 2011 they launched the 2.0 follow-up version.44 As units of coordination, issues are allocated as tasks and managed via the Issue Dashboard45, which looks similar to an email inbox. An issue has a “gravitational core”, drawing developers towards a project. Issue Tracking is about managing these issues, but also about integrating the “hooks”46 they provide in other features such as Search (Figure 5.1).47
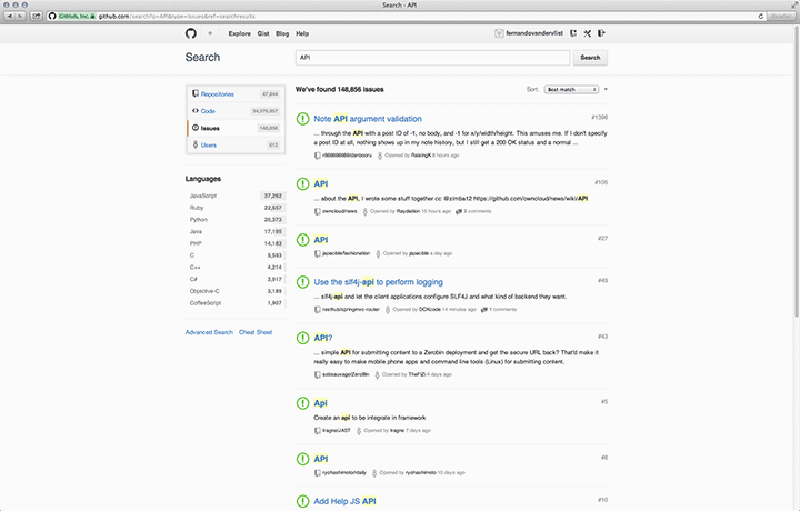
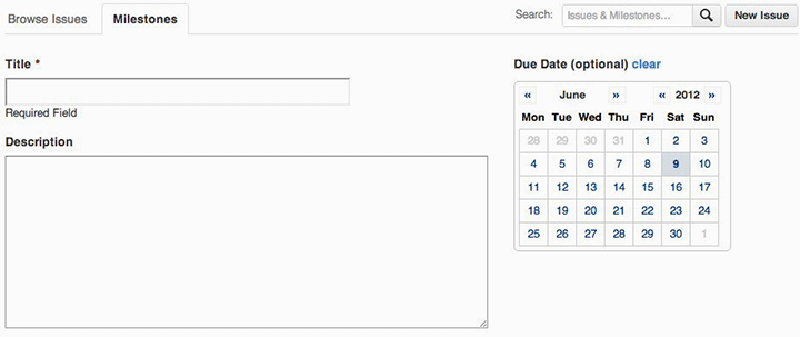
Three features complement each other and make that issue tracking is integrated into the platform. First, with the assignment feature a particular developer can be assigned to work on a task. Assignment is useful because it is “captured” (Agre [1994] 2003) and made visible to other developers as well, which prevents developers from working on the same things, and gives confidence in the project’s progress. Second, progress is measured with so-called milestones. Milestones enable the grouping of issues and focusing your issues within time blocks; indicating fixed points on the timeline of a project or issue (Figure 5.2). Third, issue labels are a simple and powerful addition that lets you add metadata to an issue. To help users on their way in adding useful labels, GitHub suggests some default labels such as “bug, duplicate, enhancement, invalid, question, and won't fix” (Bitner 2012) (Figure 5.3). These labels seem to result in a mixture of actual issue descriptions such as “bug” and issue statuses such as “won't fix”. Labels are not only useful as organising mechanism, but also enable folksonomy-based filter and search mechanisms. Behind each of these features, the notion of the “perpetual beta” (O’Reilly 2005) appears as an implication for collaboration on GitHub. Perpetual beta replaces the software release cycle in favor of the open-source maxim to “release early and often, delegate everything you can, [and] be open to the point of promiscuity” (Raymond 1998). There are only versions, which are themselves assemblages of other versions, coordinated through issues. As Jim H. Morris notes, interaction between users and servers go over the net, so they can be recorded and replayed, which can be used for much more effective bug analysis and performance measuring (2006). It also has consequences for the way features are implemented. They are not distributed as updates, rather it is a continuous feedback loop where features are implemented in rudimentary form and tested by the users. Users thus become passive co-developers.
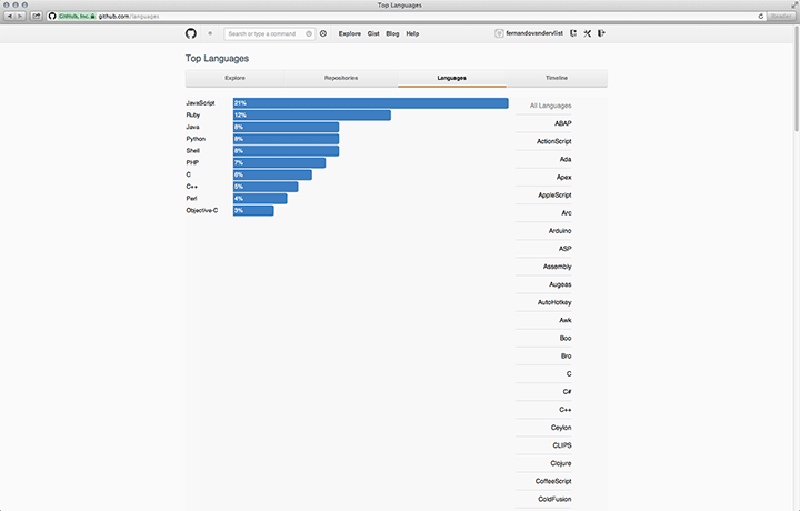
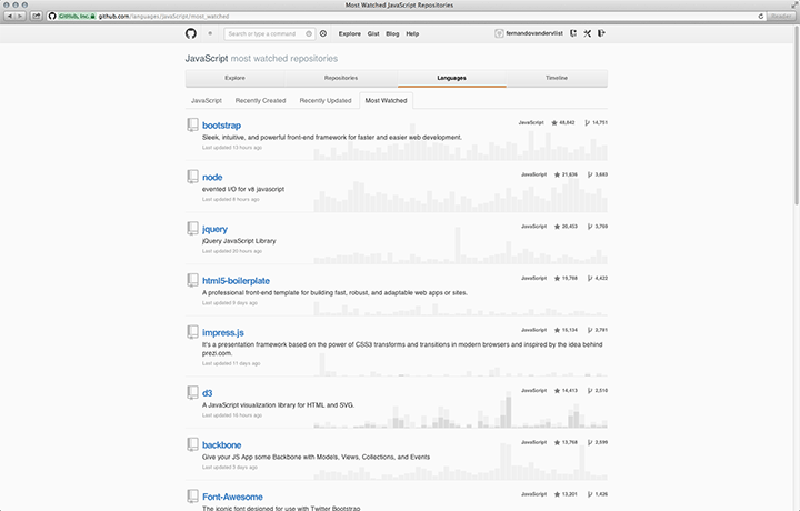
A consequence of issue-oriented coordination is the integration of code reviewing48 into the default workflow. As in any development process, reviewing your own work or the work of other peers is an essential part of the process that both quality and legitimacy often depend on. When source code can be publicly distributed and modified this can create an environment that supports constructive criticism. Assuming that in a typical collaboration not all developers will be professionally trained software engineers, collaborative development will be interdisciplinary in essence. This means that it is also necessary to keep in mind that, to a certain extent, teams become dependent on a number of shared, established concepts and skills. Source code scrutiny assumes a certain level of code literacy. In his introduction to Software Studies: A Lexicon – a seminal work that tries to establish a common vocabulary that binds thinking and acting together within a professional community (2008, 9) – Matthew Fuller identified this required skill as well. Caroline Bassett paraphrases this: “Fuller argues that the capacity to engage with code-based production and to engage with technicity of software through the “tools of realist description” requires certain technical skills, alongside skills that come from disciplines at some distance from computer science and the contained project of realised instrumentality it prioritises” (2012, 122). Bernhard Rieder and Theo Röhle also linked code literacy specifically to source code scrutiny: “[the] possibilities for critique and scrutiny are related to technological skill: even if specifications and source code are accessible, who can actually make sense of them?” (2012, 76). In order to review code, then, one would first need to learn how to both read and speak code. Moreover, it becomes even more complicated when we consider the amount of different languages used on GitHub.49 Although with 21% of the projects written in JavaScript, there currently seems to be a preference for this programming language.50 However, this is also the exception. Most languages are only used by a tiny group of collaborators, resulting in language barriers. For this reason, there is an overview51 for each language that shows a number of metrics on projects and the developers about how particular languages have recently been used (Figure 5.4). On top of different language preferences, programmers also use different vocabularies, naming conventions, or solutions to get something working.52 There is never just one solution to solve any problem, which is exactly why computer programming53 can be a deeply creative act and why the style of solution is important as well.54

5.3. Task-Oriented Development Communities
“Social learning” (Bandura 1977) is an important consequence of knowledge sharing and community building on GitHub. Developers can collaborate with a shared repository or with Pull Requests.55 This fork and pull model of collaboration allows for independent work by pushing changes, without upfront coordination, and without requiring access be granted to the source repository. Less commitment is required, reducing friction for new contributors. Jerad Bitner notes:
Pull requests in general are great means of peer review and have helped to keep the quality of code up to everyone’s standards. There’s a bit of overhead in that it may take a little longer for some new piece of code to be merged in, so plan accordingly. But this also means we find bugs sooner, typically before they're actually introduced into the master branch of the code. (2012)
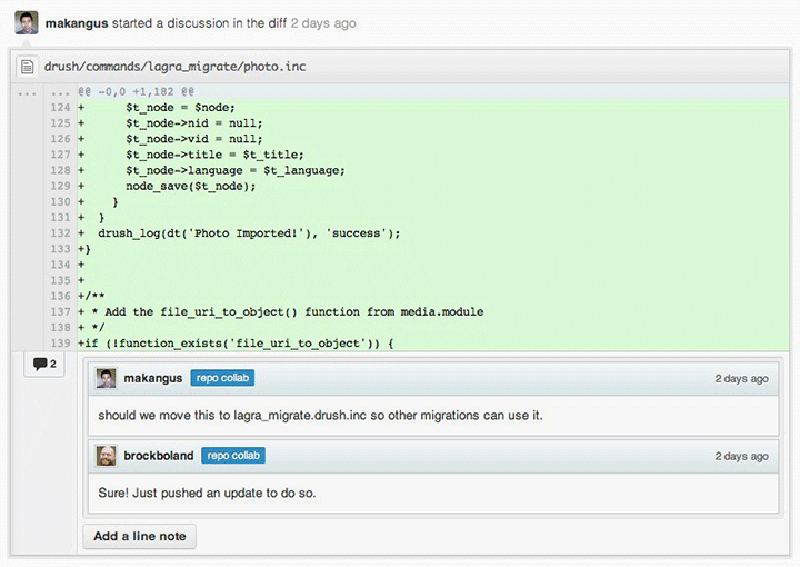
By either forking or branching, developers can suggest modifications to the existing code, or contribute new code. The project maintainer then decides which suggestions will be implemented. Four features work together to enable commenting and discussion. First, in-line commenting keeps everyone participating in the project in the loop with changes that are happening. This allows for intervention on the issue-level, which is an important aspect in terms of involvement and influence.56 Second, commit comments can be used to annotate commits with a comment. These comments also show up in activity feeds and each repository has its own comment feed.57 This makes it possible to communicate in a clear and direct way if there are questions or comments on a particular commit. Informal annotation thus becomes part of the process (Figure 5.5). Third, Gist offers a quick way to share snippets of code with others, and one great advantage is that each gist is also a fully forkable git repository.58 Considering the workflow of a typical programmer, where code is often scraped from a wide variety of places and recombined into something new, this is an important addition to the toolkit. Snippets can easily lead to informal dialogue about objects (Figure 5.6). Fourth, the blame feature shows you who are responsible for changing each line in any file of a project.59 This is not so much a feature to blame a co-developer for doing something wrong, as it is a resource (Figure 5.7). It also brings to the fore that every action on GitHub is publicly attributed to a user profile (section 6.1.). This kind of knowledge sharing directly affects community building. When developers find solutions to problems, they often start watching these (Dabbish et al. 2012). They receive updates on the progress and changes as they are made and learn about how others seek solutions to their problems, resulting in “development neighbourhoods”60 around issues.
In an empirical study on social forking in open source software development, Fung et al. (2012) show that forking – the creation of a new, independent repository by cloning the artifacts from another project (Bauwens 2005) – is poorly understood as a practice in research, because it is often assumed to be damaging to the open source community.61 According to Jon Loeliger, forking could either reinvigorate or revitalise a project, or it could simply contribute to strife and confusion on a development effort (2009, 231). By looking into nine JavaScript programming communities on GitHub, the empirical study by Fung et al. showed that: “forking was actively used by community participants for tasks such as fixing defects and creating innovations. “Forks of forks” were also utilised to form sub-communities within which specific aspects of an OSS product line were nurtured” (2012). Especially interesting here is the notion of “forking a fork”, which constitutes a secondary-level, or even tertiary-level fork and indicates a recursive division of issues into ever smaller units. Another interesting observation is that sub-communities are formed and move along with these forked issues. Ultimately, forking is part of the set of features that primarily aim to direct innovation. Instead of submitting commits to a project in development, forking means creating your own independent path. It follows from having an idea about the project that is somehow different from the views behind the initial project. Once forked, the project is treated like any other (it is the default workflow), and as such it can be watched or followed by new users that think alike. Administrative rights (and credit attribution with it) for the fork remain with the user that has created the initial fork. On the social level, this creates an environment where developers gain reputation by having adopted new and interesting projects. Users with a higher reputation according to the system will also have a greater influence in the diffusion of innovations (Rogers 1962).
Forking produces specific modes of collaboration. To illustrate this, the case of what Jesús M. González-Barahona termed “light forks”62 is useful. According to Rigby et al.: “In contrast to a fork, a light fork exists when a developer makes specific changes to part of the system, but keeps the core or most of the code the same. An example of this style of fork is a Linux kernel modified for handheld devices” (2010, 28–29, original emphasis). This emergence of light-forking is a direct consequence of a particular mode of collaboration that is enabled through that feature. In the case of the Linux kernel,63 for example, there are regular updates in different parts of the tree.64 The authors note that these changes are usually only accepted when they are not too specialised or narrowly focused, which is why the developers must maintain their own light-fork (28). Light-forks combine the ability to keep changes in code in version control, while at the same time staying up to date by pulling changes from the remote repository as they occur (29). Light-forks are a solution to prevent problems of messy merging processes, but also constitute a unique mode of collaborating that is both continuously up-to-date – as it maintains its linkages to the remote – and is at the same time completely yours to work with – as a separate repository. Still, however, the basic implications for innovation, knowledge sharing, and community building remain the same. Fung et al. make a distinction between two layers of abstraction on which forking is utilised: endogeneous and exogeneous. “[The former] occurs within a community of social developers who work on forks for the same software product line … [and the latter] refers to the creation of forks accross communities of social developers” (2012). This distinction shows how forking is linked to community building and knowledge sharing. In fact, one could argue that communities are continuously reassembled because the issues (or forks) they are connected through are continuously imported and exported between different communities. This community merging is interesting to consider as it occurs simultaneously with the merging of code artefacts. In organisations, when such a merger would occur, there are huge consequences and it might take years before a large merge is completed. On GitHub this is not the case, which shows again that an issue-oriented coordination is much more flexible, which (not coincidentally) is also one of the pillars of any good distributed system (Tanenbaum and van Steen 2007).
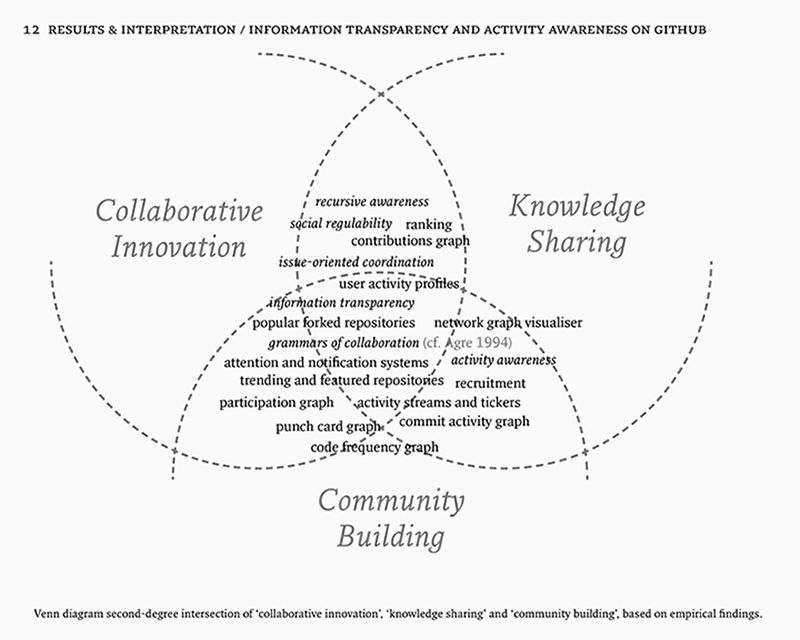
6. Information Transparency and Activity Awareness on GitHub
In the previous section I have argued how the open source philosophy initiates conditions for collaboration on GitHub. Questions of ownership have been rephrased as matters of permission and access, which has caused a reconfiguration of the public and private. In this reconfiguration, issues are the vehicles that guide collaboration, which is reflected in the integration of issue tracking. Communities become task-oriented, which illustrates that collaboration is coded or programmed. When working in the same physical space, there is always a level of awareness of each other’s activities. On GitHub, awareness systems attempt to recreate that awareness by providing all collaborators with the same mutual knowledge (Gross et al. 2005). Awareness systems such as notification systems and activity streams coordinate and synchronise task-oriented collaborative activity. In this section I look at the system as a whole to better understand information transparency and activity awareness on GitHub. The whole is not just the sum of its parts. More is different, because behaviours emerge as a result of a wide array of actions woven together into a global system.
6.1. Grammars of Collaboration
The dominant paradigm to achieving activity awareness is to create an environment of information transparency (Dabbish et al. 2012; Redmiles et al. 2007; Gross et al. 2005; Sarma et al. 2001). Activity awareness on GitHub is no exception. Philip E. Agre introduced the concept of “capture” as an alternative to the surveillance model of privacy issues. For Agre, these models are cultural phenomena. Capture is a set of metaphors that has different components, which he contrasts point-by-point with the surveillance model ([1994] 2003, 743–744). The surveillance model has its origin in political theory, while “capture” has roots in the practical application of computer systems (e.g. tracking, tracing) (744). Tracking systems keep track of significant changes in an entity’s state (742). We see these on GitHub as well, for instance in the tracing of milestones, forks, branches, and top programming languages. Tracing and attribution of activity occur on every level, which makes capture useful as a structural model to understand how activity awareness is achieved through information transparency.
Grammars of action are central to this model, for they specify “a set of unitary actions … [that] also specifies certain means by which actions might be compounded” (746). Using examples such as organisational coordination and knowledge representation in AI systems, Agre shows that they are not about specific sequences of input and output, but rather about structuring human action: “The capture model describes the situation that results when grammars of action are imposed upon human activities, and when the newly reorganised activities are represented by computers in real time” (746). Agre then divides the model in five stages that constitute a closed loop: analysis, articulation, imposition, instrumentation, and elaboration. In the elaboration stage, the captured activity can be stored, inspected, audited or merged with other records and is thus subject to analysis again, reinvigorating the cycle (746–747). As a set of linguistic metaphors, capture is not about control or what is visible on the screen, but rather constitutes the rules of the game – the grammar we are allowed to collaborate through.65 Worth noting is that these grammars do not need to be externally implemented, because action is impossible beyond this grammar. Although challenged66, it is useful to consider the capture model – and grammars of collaboration with it – for it shows that, from a system point-of-view, the local is connected to the global as two sides of the same coin. The local is found in the global, just as the global is found in the local.
User profiles are the nerve centres or hubs of activity streams. They show us that each of the pieces of data published is also being captured and processed. In order to track the activity of a developer, there needs to be a certain unique identifier. On GitHub this identifier is coupled with a unique username, to which an account is linked. You cannot collaborate if you are not logged in with the right password. A user profile, then, represents the activity of that, and only that, unique user account (Figure 6.1). Although it may seem obvious, it is important for tracking as well as attribution. All user activity is captured and processed by the system. Such information is needed to create an information-transparent environment, which creates a sense of continuous awareness among developers that follow each other. To illustrate, consider forking again. Information about forking is used to rank projects in trending or featured repositories, or popular forked repositories. As a programmed action – where the action is part of a programmed sequence or algorithm – this data can be analysed and returned as feedback to the user. It is because the actions are captured that they may also be used to publish what has been updated, which in turn can be analysed by the system or its users to infer relevancy (Figure 6.2). As a second example, the activity visualisations on the user’s Open Source Contributions are generated automatically by analysing the quantity of recent activity and returning it as public information afterward.67 This information specifically entails Pull Requests, issues opened, and commits.68 Counting is treated differently than receiving credit. Contributions are counted only if they land in the master branch of the upstream. As long as you are contributing to the master branch in your own fork, it does not count. Credit is received when you open an issue, propose a pull request, or author a commit. Credited or not, all activity will still be part of the public activity feed. As long as the “what”, “when” and “where” are tracked, nothing has to go unnoticed (cf. Lessig 2006, 38–60). This means that collaboration becomes regulable, and because contributions are authenticated (i.e. linked to an identity) the system harnesses complex social values such as status and reputation.
This regulability thus leads to a second major consequence of information transparency, which could be called recursive awareness. By this I mean the social system constituted by a repeated transparency in a self-similar way that instantiates complex social value systems such as reputation management, and is constituted through ranking, starring, watching watching, member recruiting, and so on. It’s easy to underestimate the value of awareness, but as Dan Ariely persuasively argued, people tend to be motivated by a sense of purpose and recognition of their efforts (2012).69 According to Dabbish et al. there is a sense of “being onstage':
Many of the heavy users of GitHub expressed a clear awareness of the audiences for their actions. This awareness influenced how they behaved and constructed their actions, for example, making changes less frequently, because they knew that “everyone is watching” and could “see my changes as soon as I make them”. (1284–1285)
The authors were also able to identify that watching was inferred as a signal of project quality, because they would assume that if many people track the progress of that project, it is most likely to be good. It is, in other words, a sign of approval from the community. Self-promotion also follows from this effect of being aware of the awareness of others. GitHub profiles are not just profiles; for recruiters they become resumes as well, because they provide a detailed overview of someone’s investment and quality of his work (Dabbish et al. 1282; Begel 2010, 34).70 There is a certain kind of stability when the overview (read resume) tracks and refers to all your activity on GitHub, which is activity that GitHub has accumulated over time and is contributing to the very projects it stores.71 Such stability is possible, then, because information transparency, and awareness with it, is recursively interwoven into a network of captured activity.
This specific programmed informational environment also instantiates what Dabbish et al. called watching watching. They observed that some respected developers acted as a kind of “curators of the GitHub project space”. Some people tend to have a similar taste in projects, which makes it useful to watch what others are watching. This is also the case when a certain developer works a lot on specific issues, consequently becoming an expert in that category of issues. As mentioned earlier, it is a programmer’s habit to use the knowledge and code that others have developed before them (e.g. copying snippets of code, forking complete projects), resulting in nested episodic collaborations.
6.2. Tracing the Network and Participation Graphs
Metrics are units of measurement that can be used to quantitatively assess a user, process, or event. As such they provide all kinds of information about the system and its use, which, among other things, gives designers of such systems an empirical foundation to improve the system (Kan 2002). There is a continuous feedback loop between design and usage (e.g. perpetual beta). As input, metrics establish a connection with the physical world, because systems can remember, predict, and adapt.
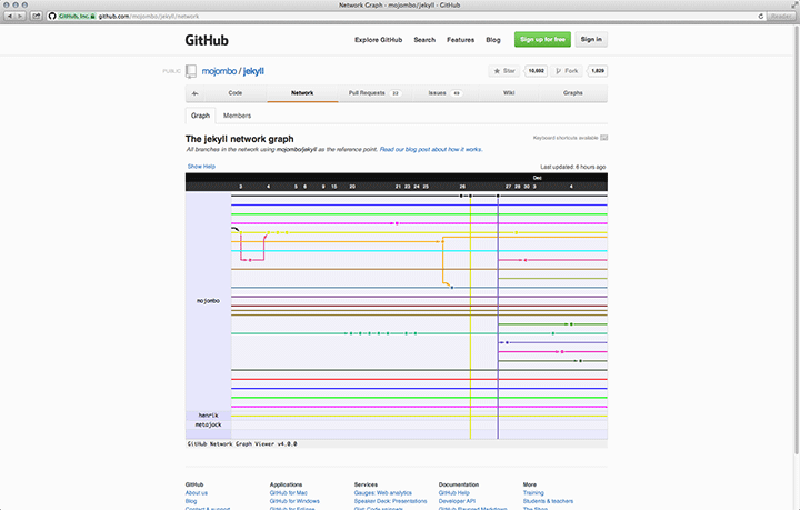
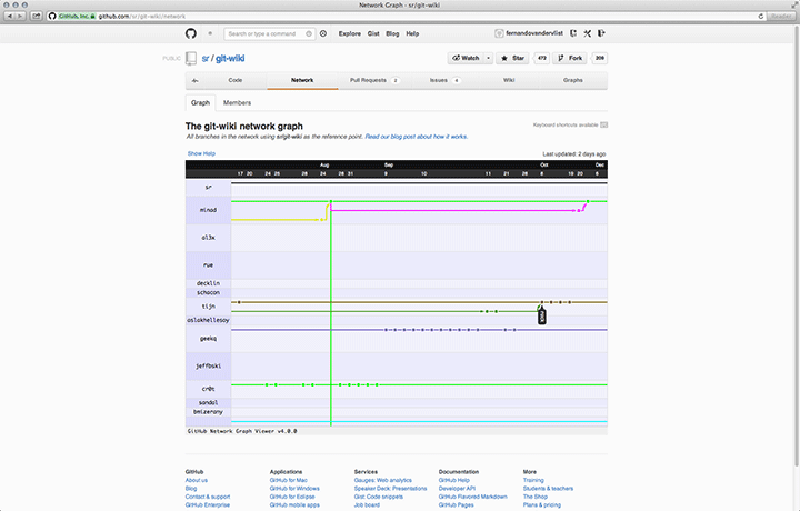
The Network Graph Visualizer72 is a feature that helps collaborators to keep track of what other collaborators have done.73 It automatically visualises the project tree into a schematic representation where a timeline with dates is plotted against usernames (Figure 6.3). When we relate this to the capture model it means that commits, branching and connected activity are captured and returned to the user in visual form. Along the way, certain assumptions are made regarding the question of what will be useful to the developers for the purpose of coordinating collaborative work. The algorithm visualises all commits, the branches, and the repositories that belong to the network. As Tom Preston-Werner notes, this method concentrates on code and not on ego74, which is to say that only contributions are shown that are not yet merged with your version of the project. In other words, it shows only activity that is relevant for the purpose of coordinating parallel lines of development. Another, perhaps less obvious assumption, is the notion that the newest commit is usually the most relevant one for a developer. By default you only see the last month or so, and to see more than that you will have to drag all the way back in time. This obviously makes it harder to find and continue working on contributions from a while back (there seem to be loose ends everywhere), reinforcing the issue-oriented mode of collaboration. In that case it makes sense to work on the newest version, because newer commits will probably have solved (part of) the issue. On the other hand, when the issue is solved, it instantly loses its relevance. Perfectly compatible with the notion of the black box: as long as it works, we should not have to think about it anymore. Is software development really only about making things work?75 On the level of visualisation, this assumption is also connected to western metaphors of time as a linear, sequential stream of events that “just takes us along”. Its horizontal, left-to-right orientation is typical of western thought (cf. Leong 2010).76
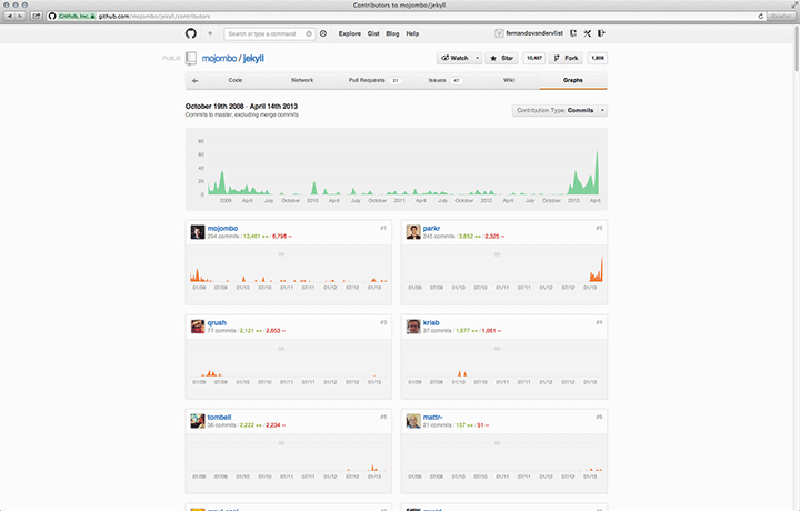
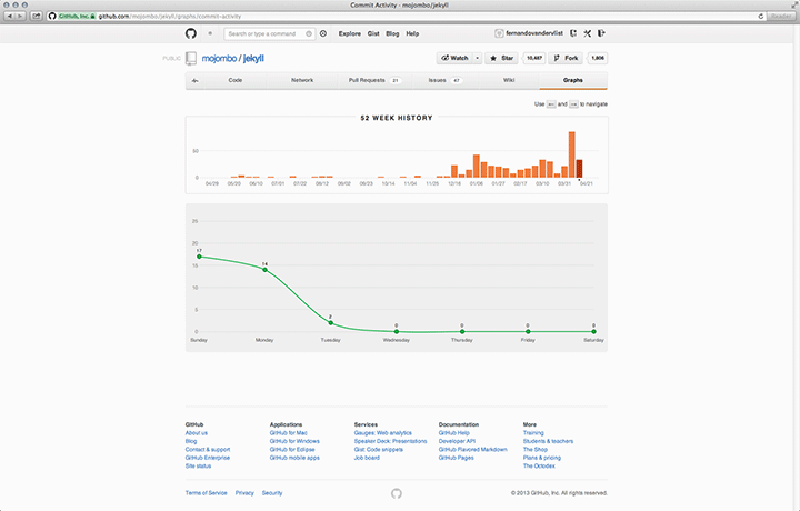
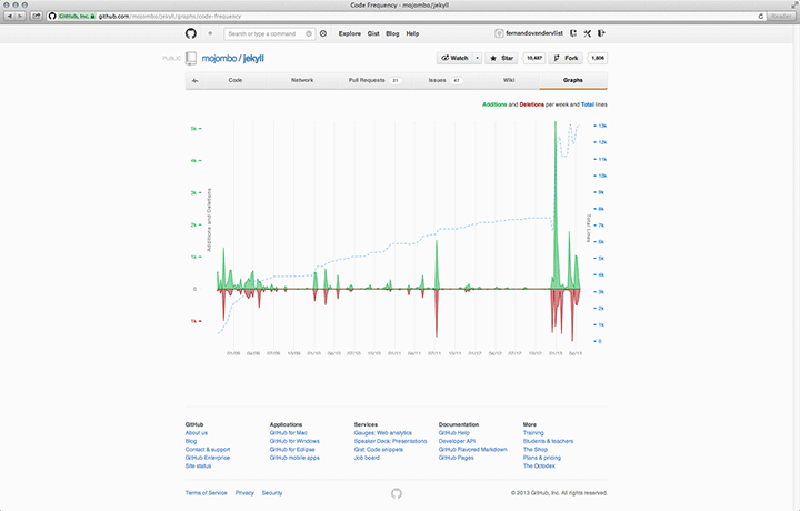
In addition to the network graph, several other computational graphs are implemented on GitHub as well. These other visualisations can be used to discover who is contributing to a project (Contributions graph), commit activity over time (Commit Activity graph), or additions and deletions during the project’s lifespan (Code Frequency, and Punch Card graphs).77 This set of graphs comes with each individual repository, and as such only covers metrics that are relevant to collaboration on that repository.78 All of these visualisations are based on metrics of user participation. In the Contributors graph we get to see who has contributed, when they committed to the master branch, their number of commits (for which they are assigned ranks), and when peaks in activity occurred (Figure 6.4). In the Commits graph the metrics are anonymised, highlighting patterns in quantity of commits over the course of a year – not quality or size of these commits (Figure 6.5). The Code Frequency graph shows additions and deletions in code quantified as the number of lines of code (Figure 6.6). And finally the Punch Card graph gives a zoomed-in account of the number of commits for each hour of the week (Figure 6.7). The graphs help users to read participation as patterns of activity, indicating to which extent that project is engaged with. It is because these graphs show the larger shifts and dynamics within a project that developers can infer a sense of legitimacy (i.e. communal approval) from them.
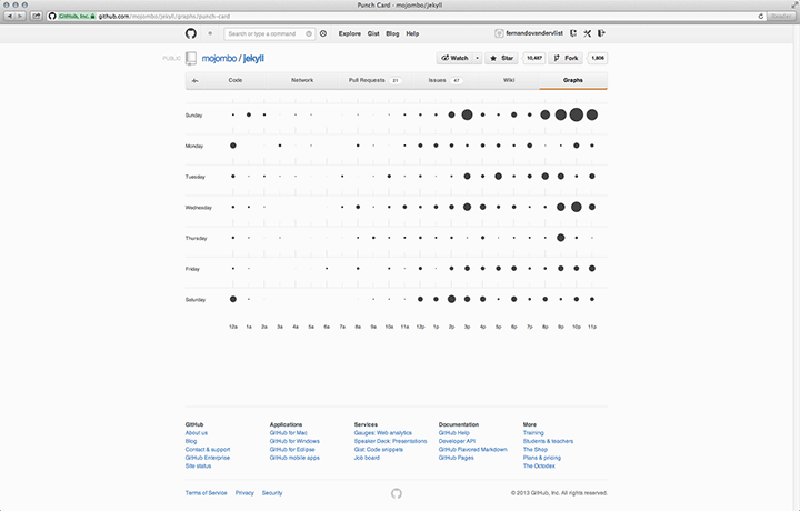
Each of these graphs is continuously updated with new data, showing that the local and global (or human and system) are continuously mirrored back to each other. The input is captured on the local level, but because it is updating in real-time, it is at the same time mirrored in the form of a visualisation; as part of the pattern. Individual contributions are always a fragment of the whole. Mirroring is used as a metaphor here, suggesting both simultaneity and difference, but also self-reflexivity. Looking into a mirror may be confronting, because it shows you things you would not see otherwise. Someone else would have to tell you. Mirroring, as opposed to tracing, may be a more appropriate metaphor, then, because synchronisation happens instantly. In this environment you do not need this other person to tell you anymore; you instantly “hear back” from the whole community over the whole lifespan of the project.
6.3. Complementary Approaches
Now that so many open source projects are being traced and developed in the same technical environment, it allows for new insights into the collaborative software development process (Heller et al. 2011; Mockus 2009). In these cases visualisation techniques could be used to locate patterns in large datasets, which could then be the starting point for further research into the emergence of such patterns. As I have tried to argue, there is a complex interplay between human action and the various systems on GitHub. Software has the ability to produce and instantiate modes of collaboration that are specific to the environment in which that software is implemented. This means that digital ethnographic research (Murthy 2008) and other ethnographic approaches79 could be a useful addition to understand how the system is adopted on the micro-scale; that is a situated account of how developers on particular projects and in specific collaborative networks use the platform as infrastructure, struggle with conflicts, or solve issues within the limitations set by the systems. One could study different networks of influence and (in)dependencies, self-censorship, the extent to which social and cultural differences are expressed and repressed by the system or the organisations, and many other things. For this kind of research, built-in versioning history, commit history and other analytics may for instance be useful to understand how particular issues have emerged, and how their solutions are constructed. This is what Richard Rogers called “in-built reflection or reflexivity” in the context of Wikipedia (Rogers 2009, 28).80
As the largest code-hosting platform, GitHub is now the main place where developers working together on open source projects organise themselves. Reputation on this platform has become a currency that has real value outside the digital community as well as within it (Dabbish et al. 1282). Because activity is public, it becomes a space where developers are recruited based on their levels of commitment, quality and number of their commits, and the type of projects they are associated with. Reversely, based on profile information such as organisation and names, developer recruitment on GitHub can also follow from real-world credentials. Another consequence is that, like other collaborative endeavours such as Wikipedia, one of the recurring issues is the assurance of quality control of shared knowledge. As on Wikipedia, this is achieved in part by what Morgan Currie called “commons-based peer production” (226–227),81 which emphasises consensus-building over the quality of a single version. Issues are resolved in disconnected instances (e.g. forks, branches) and are later merged with the master branch. This happens in an environment of organisational hierarchy (e.g. upstream, pull or merge requests, access permissions), but versions can always be forked or rearranged into different assemblages and different organisations. In contrast to Wikipedia, GitHub is also not expected to uphold a certain level of consistency and quality control over all its contents.82 Instead, these concerns are limited to the scale of the project network.
The social in social coding represents that we do not only look and imitate others, but we can actually learn from that. This is why we are able to accumulate knowledge and increase the pace of learning (Pagel 2011). Smaller social groups usually equals less innovation, less imitation, and less social learning. Git causes collaboration to be fragmented into communities, but these are not mutually exclusive but nested (section 4.3.). Through watching, following, public activity streams, notifications, commit contributions, or discussions you can be part of many different groups at the same time. This means that social learning can easily and effectively spread across these disconnected networks that are connected through the activities of developers. The rate of social learning and accumulation of knowledge highly increases through adaptation and imitation. This raises questions regarding the relationship between the number of languages on GitHub and what this means for the pace of innovation. In natural languages, for example, language is considered as a barrier surrounding and protecting a culture and its identity and knowledge (Pagel 2011). These rings of language tend to slow the pace of adoption of ideas and therefore also the pace at which they flow through a global society. As a hub of collaborative activity, GitHub removes many of these barriers, but to what extent does this theory hold when different programming languages are deployed? At the very least, the interface is standardised; across the globe, everyone is subject to the same grammars of action. Formal artificial languages (e.g. programming languages) also remove some of these barriers of natural language, which would otherwise be a big issue for “global software development”. Clearly, there is much more territory worth exploring.
7. Conclusion
This research contributes to and elevates the contemporary academic debate on technicity as part of the broader project of software and platform studies. As such it informs the design and implementation of platforms that try to harness the many ways in which systems and information transparency can support collaborative innovation, knowledge sharing, and community building. By examining the constitutive relations between technical infrastructures and specified human actions, I have tried to show that software has the ability to produce and instantiate modes of collaboration that are specific to the environment in which that software is implemented. Systems of storage and versioning, access protocols, grammars of collaboration, social regulation, “social learning” (Bandura 1977), activity streams and visualisations, and so on, shape the conditions for these context-specific kinds of innovation, knowledge sharing, and community building to emerge.
As a distributed system for revision control and source code management, Git prefers modes of collaboration that are episodic or continuous. This resulted in a different approach to projects as nested code assemblages to which communities are attached, and with issues acting as hooks. Among the implications is the replacement of software release cycles by “perpetual beta” (O’Reilly 2005), and cumbersome organisations by task-oriented development neighbourhoods that are formed because code is a social object that structures collaborative efforts. Free distribution and access to source code and implementation are essential to collaborative effort on GitHub, which lead me to rephrase the question of ownership as one of accessibility and permission protocols and lead to a discussion of how the public and private had been reconfigured on the Web towards a “neodemocracy” (Dean 2003). Implications of this shift concern the central role of issues as units of collaboration, and how these issues are tracked and integrated into the platform as searchable units or through task allocation and issue management. Because issues and tasks are concrete units of collaboration, they can be measured (e.g. lines of code, difficulty, date stamps), compared (compare view, blaming, merging), allocated (e.g. to trained professionals, amateurs), and processed by the system (e.g. activity metrics). This leads to particular forms of knowledge sharing and learning such as disconnected issue solving, tiny snippets of code, or watching watching. Information transparency and activity awareness can greatly enhance the coordination of distributed efforts. As a result of a predefined grammar of collaboration, every action can have “an equal and opposite reaction”83 from the system that can be distributed (e.g. visualisation, notification, stream), which instantiates social regulability enabled by recursive awareness, and resulting in a complex system of social values such as status, skill, and reputation. In the discussions of social forking, Gist, and (re-)merging, it became clear that knowledge is shared through activity feeds and other automated systems that capture this activity. Information transparency and activity awareness make communities and their efforts visible and create opportunities for social learning and source code scrutiny.
I propose to continue these efforts to develop a “thick” understanding of software and platforms, and the critical role that systems and code play in shaping the technicity of our everyday lives and problems. There is relatively little research on the role of software in this regard. At least not on how software is constitutive as both product and process; how code emerges. This is also why we need more situated studies to show how technicity has implications on the micro-level, and in order to understand to what extent a system interpellates people to its logic. Software is not just supporting human faculties; it is rather a complex constellation of negotiations between humans and technology. The implemented features convert collaboration into a coded (programmed) concept, which leads to workflows that are specific to the GitHub environment (e.g. light-forks, social forking, episodic and continuous collaboration, issue solving in disconnected instances, the use of feature branches, (re-)merges, the fork and pull workflow). Collaboration becomes in an informational environment of global/local mirroring of captured information, which also imposes particular grammars of collaboration. Specific technological constellations are constitutive of particular kinds of networks such as knowledge-based social learning networks, and task-oriented development communities, where projects exist as nested code assemblages, to which communities are attached through issues. On the other end, we also need studies that focus on larger power relationships that shape the development of platforms or software as part of larger “ecosystems” (van Dijck 2013; Langlois 2011; Gillespie 2010). Related to this, and as van Dijck also stressed, we should also be deconstructing what meanings developers impute into the platform, its goals and its features (2013, 11). Technologies will keep changing, but an understanding of coded incentives could indicate broader discourse networks and provide insight into which direction the platform might evolve in the future.
8. Acknowledgements
Many thanks to Carolin Gerlitz and Esther Weltevrede for their research seminars, helpful comments throughout the writing process, and also for ensuring that this work could be submitted in English. Thanks also to those peer students who commented on earlier drafts. Last but not least, I am grateful to Jessica de Jong and Anlieka Marconi for their comments and taking the time to look over the structure, spelling, and grammar of the English writing.
9. Endnotes
- Chris Wanstrath, P. J. Hyett, and Tom Preston-Werner. GitHub. GitHub, Inc., 10 Apr. 2008. Web. 10 Feb. 2013. <https://github.com/>.
- Rob Sanheim. “Three Million Users.” The GitHub Blog: Watercooler. GitHub Inc., 16 Jan. 2013. Web. 22 Mar. 2013. <https://github.com/blog/1382-three-million-users>.
- See also Bucher 2012; Dodge and Kitchin 2011; Niederer and van Dijck 2010; Mackenzie 2002.
- It is worth mentioning that Caroline Bassett argues that there is a division between UK-based or European critical approaches (such as Fuller 2008, 2003; Rieder 2013; Berry 2012) and US-based de-politicised formalism (such as Manovich 2011) in relation to canonisation (2012, 122).
- See also Gillespie 2013, 2010.
- See also Gerlitz and Helmond 2013; Rieder and Röhle 2013; Weltevrede and Helmond 2012; Niederer and van Dijck 2010.
- Paraphrasing Adrian Mackenzie (2002), Martin Dodge and Rob Kitchin describe technicity with an emphasis on the social context (which is always more than just a backdrop): “Technicity refers to the extent to which technologies mediate, supplement, and augment collective life; the unfolding or evolutive power of technologies to make things happen in conjunction with people” (42).
- Cf. Dodge and Kitchin 2011, 59–61.
- See also Cronin 2003, 55.
- Chris Wanstrath. “We Launched.” The GitHub Blog: New Features. GitHub Inc., 10 Apr. 2008. Web. 1 Apr. 2013. <https://github.com/blog/40-we-launched>.
- See also de Alwis and Silito 2009.
- See also Benkler 2005; Wood 2010; Biddle et al. 2003; Ripeanu 2001.
- See also Harper and Kivilinna 2012; Loeliger 2009; Yip, Chen, and Morris 2006.
- Following in the footsteps of an earlier approach to group support and understanding system requirements called “office automation” had run out of steam (Grudin 1994, 19).
- See also Goguen 1997; Schmidt and Simone 1996; Rienhard et al. 1994; Schmidt and Bannon 1992.
- See also Dabbish et al. 2012; Heller, Marschner, Rosenfeld, and Heer 2011; Sarma, Redmiles and van der Hoek 2008; Redmiles et al. 2007; Sarma and van der Hoek 2007, 2003; Gross, Stary, and Totter 2005; Viégas, Wattenberg, and Dave 2004; Carroll et al. 2003; Schmidt 2002.
- See also Galloway 2004.
- See also Harper and Kivilinna 2012; Stallman 1985.
- See also Moran 2009; Dirlik 1996.
- The GitHub Blog. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. <https://github.com/blog>, The GitHub Blog: New Features. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. 2013. <https://github.com/blog/category/ship>, The GitHub Blog: Engineering. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. 2013. <https://github.com/blog/category/engineering>, The GitHub Blog: Enterprise. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. 2013. <https://github.com/blog/category/enterprise>, The GitHub Blog: Meetups. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. 2013. <https://github.com/blog/category/drinkup>, and The GitHub Blog: Watercooler. GitHub, Inc., 18 Feb. 2008. Web. 14 Apr. 2013. <https://github.com/blog/category/watercooler>.
- GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013 <https://help.github.com/>.
- “GitHub Terms of Service.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-terms-of-service>, “GitHub Security.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-security>, “GitHub Privacy Policy.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-privacy-policy>, “GitHub Trademark Policy.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-trademark-policy>, “DMCA Takedown.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/dmca-takedown>, “Responsible Disclosure of Security Vulnerabilities.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013 <https://help.github.com/articles/responsible-disclosure-of-security-vulnerabilities>, “Name Squatting Policy.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/name-squatting-policy>, and “Supported browsers.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/supported-browsers>.
- “GitHub Security.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-security>, and “GitHub Privacy Policy.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/github-privacy-policy>.
- GitHub: Status. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://status.github.com/>.
- From a platform analysis point-of-view I should mention as well that I am writing this as someone who is new to GitHub, which puts me in the position of an explorer rather than a user; moving into unknown territory, but informed and directed towards a specific purpose.
- Clifford Geertz borrowed the term from Gilbert Rule who discussed it in two of his essays to point at “the unphotographable richness between [for example] a twitch or wink” (Geertz 1973, 6). Geertz then extended this notion in order to establish a methodological basis for an interpretive theory of culture (3–30, ch. 1).
- Available for download from <http://git-scm.com/downloads>.
- See also Sink 2011, 1.
- Ben Collins-Sussman, Brian W. Fitzpatrick, C. Michael Pilato. “Version Control Basics: Chapter 1. Fundamental Concepts” Version Control with Subversion: For Subversion 1.7 (Compiled from r4460). Red Bean Software, 2011. Web. 8 Apr. 2013. <http://svnbook.red-bean.com/en/1.7/svn.basic.version-control-basics.html>.
- See also Chun 2011. This “circular-causal” relationship has a long-standing tradition in computer ideology and history, and stems from the cybernetic tradition initially defined by Norbert Wiener in 1948.
- For discussions of resistance of pervasive computing and “ethics of forgetting” see Dodge and Kitchin 2011, 2007; Marx 2003.
- For example, see Kaare. “Is this project dead. Add collaborators?” GitHub. GitHub, Inc., Mar. 2013. Web. 5 May 2013. <https://github.com/AvianFlu/ntwitter/issues/100>.
- For an overview of popular watched projects as of 16 Aug. 2011, see Kevin McCarthy. “GitHub’s 50 Most Popular Projects.” BostInno. 16 Aug. 2011. Web. 18 Mar. 2013. <http://bostinno.com/2011/08/16/githubs-50-most-popular-design/>. To compare with the current list, see “Popular Starred Repositories.” GitHub. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://github.com/popular/starred>.
- “Fork (software development).” Wikipedia, the free encyclopedia. Wikimedia Foundation, Inc., n.d. Web. 8 Apr. 2013. <http://en.wikipedia.org/wiki/Fork_(software_development)>.
- See Diego Calleja. “Linux 3.3.” Linux Kernel Newbies. WikiWall, 18 Mar 2012. Web. 4 May 2013. <http://kernelnewbies.org/Linux_3.3> and Steven J. Vaughan-Nichols. “Android and Linux re-merge into one operating system.” ZDNet. 19 Mar. 2012. Web. 8 Apr. 2013. <http://www.zdnet.com/blog/open-source/android-and-linux-re-merge-into-one-operating-system/10625>.
- Deleted.
- “What are the different access permissions?” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/what-are-the-different-access-permissions>.
- For example, Linus Torvalds is both development coordinator and lead developer of the Linux mainline kernels (also called vanilla).
- “Plans & Pricing.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://github.com/plans>.
- Recently, a routine system email was accidentally sent to many of the Enterprise users. The email addresses were included in the “To” field, making them visible to everyone who received the email. Some users expressed serious concerns regarding GitHub’s ability to keep their client’s code private. See Brian Doll. “Today’s Email Accident.” The GitHub Blog: Enterprise. GitHub, Inc., 19 Mar. 2013. Web. 4 May 2013. <https://github.com/blog/1440-github-enterprise-email-incident-today> and Ingrid Lunden. “3K+ Emails of GitHub Enterprise Users Outed in Email and Then Posted on Pastebin [Updated].” TechCrunch. AOL Inc., 19 Mar. 2013. Web. 20 Mar. 2013. <http://techcrunch.com/2013/03/19/3k-emails-of-github-enterprise-users-outed-in-email-and-then-posted-on-pastebin/>.
- “Features / Project Management.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://github.com/features/design/issues>, and “What are the different access permissions?” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/what-are-the-different-access-permissions>.
- Tom Preston-Werner. “GitHub Issue Tracker!” The GitHub Blog: Watercooler. GitHub Inc., 15 Apr. 2009. Web. 22 Mar. 2013. <https://github.com/blog/411-github-issue-tracker>.
- Ibid.
- Kyle Neath. “Issues 2.0: The Next Generation.” The GitHub Blog: Watercooler. GitHub Inc., 9 Apr. 2011. Web. 22 Mar. 2013. <https://github.com/blog/831-issues-2-0-the-next-generation>.
- Brian Lopez. “Issues Dashboard.” The GitHub Blog: Watercooler. GitHub, Inc., 27 Sept. 2011. Web. 5 May 2013. <https://github.com/blog/941-issues-dashboard>.
- By hooks I mean the anchors that establish a cognitive or emotional link. As I have argued elsewhere (2013) in the context of memetic theory, these matching receptors form the necessary condition for contagion from source to target.
- Even though issues are important, if not the main organising units, there is no such thing as issue-only access permission. This can, however, be achieved by cloning the issues; deploying a second repository that would only contain the issues. See “Issues-only access permissions.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/issues-only-access-permissions>.
- “Features / Project Management.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://github.com/features/design/codereview>.
- “Top Languages.” GitHub. GitHub, Inc., n.d. Web. 14 Apr. 2013 <https://github.com/languages>.
- Statistics retrieved on 14 Apr. 2013 from <https://github.com/languages>.
- “Top Languages.” GitHub. GitHub, Inc., n.d. Web. 14 Apr. 2013 <https://github.com/languages>.
- Dodge and Kitchin identified several such different kinds of programming: “Programming extends from the initial production of code, to refactoring (rewriting a piece of code to make it briefer and clearer without changing what it does), to editing and updating (tweaking what the code does), to integrating (taking a piece of code that works by itself and connecting it to other code), testing, and debugging, to wholesale rewriting.” (2011, 26, ch. 2).
- Here I understand programming as not just the writing of machine-readable instructions for a machine, but – in line with Dodge and Kitchin – as having an “ontological capacity”: “programming seeks to capture and enact knowledge about the world – practices, ideas, measurements, locations, equations, and images – in order to augment, mediate, and regulate people’s lives” (26).
- Although for many programming may just be about making things work, it is also about creativity and empowerment. Two ideals have emerged in this regard; obfuscated code, and elegant code. (Fuller 2008; Knuth 1974; see also Dodge and Kitchin 2011, 111–134; Maeda 2004).
- “Using Pull Requests.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/using-pull-requests>, and “Creating a pull requests” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/creating-a-pull-request>.
- Brock Boland. “Intro to Github Pull Requests.” Vimeo. Vimeo, LLC., May 2012. Web Video. <http://vimeo.com/41045197>, Jerad Bitner. “Managing Projects with GitHub.” Lullabot. 20 June 2012. Web. 12 Apr. 2013. <http://www.lullabot.com/blog/articles/managing-projects-github>, “Creating a pull requests.” GitHub: Help. GitHub, Inc., n.d. Web. 14 Apr. 2013. <https://help.github.com/articles/creating-a-pull-request>, and “How Do I Deal with a Team Member Who Refuses to Make Comments in Code?” Ars Technica OpenForum. 16 Feb. 2013. Web. 18 Feb. 2013. <http://arstechnica.com/civis/viewtopic.php?f=2&t=1194507&start=80>.
- Chris Wanstrath. “Commit Comments.” The GitHub Blog: New Features. GitHub, Inc., 10 Apr. 2008. Web. 14 Apr. 2013. <https://github.com/blog/42-commit-comments>.
- Bryan Veloso. “Welcome to a New Gist.” The GitHub Blog: New Features. GitHub, Inc., 11 Dec. 2012. Web. 14 Apr. 2013. <https://github.com/blog/1276-welcome-to-a-new-gist>.
- Scott Chacon. “Playing the Blame Game.” The GitHub Blog: New Features. GitHub, Inc., 18 Nov. 2008. Web. 14 Apr. 2013. <https://github.com/blog/228-playing-the-blame-game>.
- The term neighbourhood seems appropriate here because it reminds of an environment where people know each other, keep tabs on what is going on, share the newspaper, and try to contribute or “give back to the community” where they can.
- See also Moen 1999 for an analysis of why open-source forking is both rare and benign.
- In his personal communication with Daniel German (2008). See Rigby 2010, 24.
- As pointed out by Eric S. Raymond (1998), Linus Torvalds” Linux kernel is an ambitious project that did not start from scratch. Instead, he would start by reusing code and ideas from MINIX, which is an UNIX-like OS created by Andrew Tanenbaum for educational purposes. Raymond links this example to prove his point that “good programmers know what to write. Great ones know what to rewrite (and reuse)”, and that “the source-sharing tradition of the UNIX world has always been friendly to code reuse”.
- It is worth noting that fork trees are different from version trees. Fork trees are made of forks, whereas version trees are made of branches. As discussed earlier (section 4.2), branches and version trees are part of the Git index and storage systems. Forks, on the other hand, create “schisms” (Hill 2005) and are used to initiate new directions for independent development; are created from a subset of the complete project; and can link together features between communities, because they can be created from multiple predecessors (Fung et al. 2012).
- Andrew Barry argued in regard to what he called “technological citizenship” that interactivity is now the dominant model for producing subjects through objects. In an interactive model, subjects are not disciplined (in the Foucauldian sense as “docile bodies”). Instead, they are allowed (Barry 2001, 129).
- For example, see Lucy Suchman’s ethnographic approach to “situated actions”, which holds that actions should not just be abstracted, because they are always the result of a complex interaction with material and social circumstances (1985, 35–46, ch. 4).
- Compare the discussion of Jodi Dean’s neodemocratic model of publicness on the Web. According to her, publicity is an ideology in the service of “communicative capitalism” (2003, 98). This is relevant for instance when considering the reputation management of developers that profile themselves as expert on particular languages. Only the newest and most recent counts. As Paul Virilio also obverved; when speed and slow compete, speed will always dominate the slow (2000).
- “Why are my contributions not showing up on my profile?” GitHub: Help. GitHub, Inc., n.d. Web. 16 Apr. 2013. <https://help.github.com/articles/why-are-my-contributions-not-showing-up-on-my-profile>.
- See also Yang and Lai 2010 for a specific study on the motivations of Wikipedia content contributors. Their study concludes that the strongest intrinsic and extrinsic motivations for contributing to Wikipedia is an internal drive to share knowledge with others (1377–1382).
- “GitHub: Can GitHub be used for recruting?” Quora. 3 Nov. 2011. Web. 21 Apr. 2013. <http://www.quora.com/GitHub/Can-GitHub-be-used-for-recruiting>.
- Matthew Fuller observed a similar moment of stability in dictionaries: “A normal dictionary comes to a point of momentary stability when it defines all the words which it uses to define all the words that it contains. Each definition, then, reaches out to all the terms used to establish its meaning in a beautiful, recursively interwoven networking of language.” (2008, 9).
- GitHub Network Graph Viewer. v4.0.0. GitHub Inc., 10 Apr. 2008. Applet. 18 Apr. 2013.
- Preston-Werner, Tom. “Welcome to a New Gist.” The GitHub Blog: New Features. GitHub, Inc., 10 Apr. 2008. Web. 17 Apr. 2013. <https://github.com/blog/39-say-hello-to-the-network-graph-visualizer>.
- Ibid.
- Many have argued that programming is in fact highly subjective (e.g. Dodge and Kitchin 2011, 23–44, ch. 1; Berry 2008, 2011), or even consider it an art in its own right (e.g. Knuth 1974).
- Ramsey Nassar recently developed the qlb programming language in his exploration of code as self-expression. This Arabic programming language that flows from right-to-left is an exploration of the role of human culture in coding and a poetic example of how a machine language is connected to cultural identity and self-expression. It highlights cultural biases by making one aware of the lack of such different languages throughout the professional field.
- Justin Palmer. “Introducing the New GitHub Graphs.” The GitHub Blog: New Features. 25 Apr. 2012. Web. 17 Apr. 2013. <https://github.com/blog/1093-introducing-the-new-github-graphs>.
- The overview of popular forked repositories on presents participation graphs that make use of some of these metrics as well. See “Popular Forked Repositories.” GitHub. GitHub, Inc., n.d. Web. 14 Apr. 2013 <https://github.com/repositories>.
- Such as Don Slater and Daniel Miller’s analysis of the hybrid uses of the Internet in Trinidad (2001).
- Cf. Currie 2012, 227.
- Borrowing the term from Yochai Benkler who introduced the notion earlier (2005, 169).
- In its terms of service, GitHub does not warrant that “the quality of any products, services, information, or other material purchased or obtained by you through the service will meet your expectations”.
- Attributed to Sir Isaac Newton as his third physical law of motion.
10. Bibliography
- Agre, Philip E. “Surveillance and Capture: Two Models of Privacy.” 1994. The New Media Reader. Eds. Noah Wardrip-Fruin and Nick Montfort. Cambridge, MA: The MIT Press, 2003. 740–760. Print.
- de Alwis, Brian, and Jonathan Silito. “Why Are Software Projects Moving From Centralized to Decentralized Version Control Systems?” CHASE ‘09 Proceedings of the 8th 2017 International Conference on Social Media 2009 ICSE Workshop on Cooperative and Human Aspects on Software Engineering (2009): 36–39. Print.
- Andrew, Barry. “On Interactivity.” Political Machines: Governing a Technological Society. London: Athlone Press, 2001. 127–152. Print.
- Ariely, Dan. “What makes us feel good about our work?” TEDxRíodelaPlata. Oct. 2012. Keynote Address. <http://www.ted.com/talks/dan_ariely_what_makes_us_feel_good_about_our_work.html>.
- Assmann, Aleida. “Canon and Archive.” A Companion to Cultural Memory Studies. Berlin: De Gruyter, 2010. 97–107. Print.
- Bandura, Albert. Social Learning Theory. Eaglewood Cliffs: Prentice Hall, 1977. Print.
- Bassett, Caroline. “Canonicalism and the Computational Turn.” Understanding Digital Humanities. Ed. David M. Berry. Basingstoke: Palgrave Macmillan, 2012. 105–126. Print.
- Bauwens, Michel. P2P and Human Evolution: Peer to Peer as the Premise of a New Mode of Civilization. P2P Foundation, 2005. Print.
- ———. “The Political Economy of Peer Production.” CTheory (2005): n. pag. Web. 14 Apr. 2013. <http://www.ctheory.net/articles.aspx?id=499>.
- Begel, Andrew, Robert DeLine, and Thomas Zimmermann. “Social Media for Software Engineering.” Proceedings of the 8th 2017 International Conference on Social Media Workshop on Future of Software Engineering Research (FoSER ’10). (2010): 33–37. Print.
- Benkler, Yochai. “Coase’s Penguin, or, Linux and the Nature of the Firm.” Code: Collaborative Ownership and the Digital Economy. Ed. Rishab Aiyer Ghosh. Cambridge, MA: The MIT Press, 2005. 169–206. Print.
- Berry, David M. The Philosophy of Software: Code and Mediation in the Digital Age. Basingstoke: Palgrave Macmillan, 2011. Print.
- ———. “A Contribution Towards a Grammar of Code.” The Fibreculture Journal 12 (2008): n. pag. Web. 5 May 2013. <http://journal.fibreculture.org/issue13/issue13_berry_print.html>.
- ———. “The Computational Turn.” Culture Machine 12 (2011): 1–22. Print.
- Berry, David M., ed. Understanding Digital Humanities. Basingstoke: Palgrave Macmillan, 2012. Print.
- Bowker, Geoffrey C., and Susan Leigh Star. Sorting Things Out: Classification and Its Consequence. Cambridge, MA: The MIT Press, 1999. Print.
- Biddle, Peter, et al. “The Darknet and the Future of Content Distribution.” Lecture Notes in Computer Science: Digital Rights Management 2696 (2003): 155–176. Print.
- Bitner, Jerad. “Managing Projects with GitHub.” Lullabot. Lullabot, 20 June 2012. Web. 12 Apr. 2013. <http://www.lullabot.com/blog/articles/managing-projects-github>.
- Blouin, Francis X., Jr, and William G. Rosenberg. “Authoritative History and Authoritative Archives.” Processing the Past: Contesting Authority in History and the Archives. Oxford: Oxford University Press, 2011. 13–31. Print.
- Bogost, Ian, and Nick Montfort. “Platform Studies: Frequently Questioned Answers.” Digital Arts and Culture, Irvine, California, 2009. Print.
- Bucher, Taina. “A Technicity of Attention: How Software ‘Makes Sense’.” Culture Machine 13 (2012): 1–23. Print.
- ———. “Want to Be on the Top? Algorithmic Power and the Threat of Invisibility on Facebook.” New Media & Society 14.7 (2012): 1164–1180. Print.
- Carroll, John M., et al. “Notification and Awareness: Synchronizing Task-Oriented Collaborative Activity.” International Journal of Human-Computer Studies 58.5 (2003): 605–632. Print.
- Cartensen, Peter H., and Kjeld Schmidt. “Computer Supported Cooperative Work: New Challanges to Systems Design.” Handbook of Human Factors/Ergonomics. Ed. Kenji Itoh. Tokyo: Asakura Publishing, 2003. 619–636. Print.
- Castells, Manuel. The Information Age: Economy, Society and Culture: The Rise of the Network Society. Vol. 1. 1996. 2nd ed. Oxford: Wiley-Blackwell, 2000. Print.
- Chacon, Scott. “Introduction to Git with Scott Chacon of GitHub.” Google Technology User Group: Silicon Valley Web JUG. Mountain View, California, 15 June 2011. Lecture. <http://www.youtube.com/watch?v=ZDR433b0HJY>.
- ———. Pro Git. New York: Apress, 2009. Print. Expert’s Voice in Software Development.
- Chun, Wendy Hui Kyong. Programmed Visions: Software and Memory. Cambridge, MA: The MIT Press, 2011. Print. Software Studies.
- Coleman, Gabriella E. “Anonymous: From the Lulz to Collective Action.” The New Everyday: A MediaCommons Project. NYU Digital Library Technology Services (DLTS), 1 Jan. 2011. Web. 2 Sept. 2012. <http://mediacommons.futureofthebook.org/tne/pieces/anonymous-lulz-collective-action>.
- Collins-Sussman, Ben, Brian W. Fitzpatrick, and C. Michael Pilato. Version Control with Subversion: For Subversion 1.7 (Compiled from r4460). Sebastopol: O’Reilly Media, Inc., 2004. Print.
- Cramer, Florian. “Animals That Belong to the Emperor: Failing Universal Classification Schemes From Aristotle to the Semantic Web.” <nettime>. Nettime.org, 19 Dec. 2007. Web. 29 Mar. 2013. <http://www.nettime.org/Lists-Archives/nettime-l-0712/msg00043.html>
- Crogan, Patrick, and Helen Kennedy. “Technologies Between Games and Culture.” Games and Culture 4.2 (2009): 107–114. Print.
- Crogan, Patrick, and Samuel Kinsley. “Paying Attention: Toward a Critique of the Attention Economy.” Culture Machine 13 (2012): 1–29. Print.
- Cronin, Blaise, ed. Annual Review of Information Science and Technology. Vol. 38. Medford: Information Today, Inc., 2004. Print.
- Currie, Morgan. “The Feminist Critique: Mapping Controversy in Wikipedia.” Ed. David M. Berry. Understanding Digital Humanities. Basingstoke: Palgrave Macmillan, 2012. 224–248. Print.
- Dabbish, Laura, et al. “Social Coding in GitHub: Transparency and Collaboration in an Open Software Repository.” Proceedings of the 8th 2017 International Conference on Social Media 2012 ACM Conference on Computer-Supported Cooperative Work (CSCW ’12): 1277–1286. Print.
- van Dijck, José F. T. M. “Facebook as a Tool for Producing Sociality and Connectivity.” Television & New Media 13.2 (2011): 160–176. Print.
- ———. The Culture of Connectivity: A Critical History of Social Media. Oxford: Oxford University Press, 2013. Print.
- Dirlik, Arif. “The Global in the Local.” Global/Local: Cultural Production and the Transnational Imaginary. Eds. Rob Wilson and Wimal Dissanayake. Durham/London: Duke University Press, 1996. 21–45. Print. Asia-Pacific: Culture, Politics, and Society.
- Dodge, Martin, and Rob Kitchin. Code/Space: Software and Everyday Life. Cambridge, MA: The MIT Press, 2011. Print. Software Studies.
- ———. “‘Outlines of a World Coming Into Existence’: Pervasive Computing and the Ethics of Forgetting.” Environment and Planning B: Planning and Design 34.3 (2007): 431–445. Print.
- Engelbart, Douglas. “Augmenting Human Intellect: A Conceptual Framework.” The New Media Reader. Eds. Noah Wardrip-Fruin and Nick Montfort. Cambridge, MA: The MIT Press, 2003. 95–108. Print.
- Finin, Tim, et al. “The Information Ecology of Social Media and Online Communities.” AI Magazine 29.3 (2008): 77–92. Print.
- Foucault, Michel. “Docile Bodies.” Discipline and Punish: The Birth of the Prison. New York: Vintage Books, 1977. 135–169. Print.
- ———. The Essential Foucault: Selections From the Essential Works of Foucault, 1954–1984. Eds. Paul Rabinow and Nikolas Rose. New York: The New Press, 2003. Print.
- Fuller, Matthew. “It Looks Like You’re Writing a Letter: Microsoft Word.” Behind the Blip: Essays on the Culture of Software. New York: Autonomedia, 2003. 137–165. Print.
- Fuller, Matthew, ed. Software Studies: A Lexicon. Cambridge, MA: The MIT Press, 2008. Print. Leonardo Books.
- Fung, Kam Hay, Aybüke Aurom, and David Tang. Social Forking in Open Source Software: An Empirical Study. School of Information Systems, Technology and Management, The University of New South Wales, Australia, 2012. Print.
- Galloway, Alexander R. Protocol: How Control Exists After Decentralization. Cambridge, MA: The MIT Press, 2004. Print. Leonardo Books.
- Geertz, Clifford. “Thick Description: Toward an Interpretative Theory of Culture.” The Interpretation of Cultures: Selected Essays. New York: Basic Books, 1973. 3–30. Print.
- Gerlitz, Carolin, and Anne Helmond. “The Like Economy: Social Buttons and the Data-Intensive Web.” New Media & Society (2013): 1–18. Print.
- German, Daniel M., and Jesús M. González-Barahona. “An Empirical Study of the Reuse of Software Licensed Under the GNU General Public License.” IFIP Advances in Information and Communication Technology (AICT) 299 (2009): 185–198. Print.
- Gibson, Eleanor J. “Perceptual Learning in Development: Some Basic Concepts.” Ecological Psychology 12.4 (2000): 295–302. Print.
- Gibson, James J. “The Theory of Affordances” Perceiving, Acting and Knowing. Eds. Robert Shaw and John Bransford. Hillsdale: Lawrence Erbaum Associates, 1977. 67–82. Print.
- ———. The Ecological Approach To Visual Perception. Hillsdale: Psychology Press, 1986. Print.
- Gillespie, Tarleton. “The Politics of ‘Platforms’.” New Media & Society 12.3 (2010): 347–364. Print.
- ———. “The Relevance of Algorithms.” Media Technologies. Eds. Tarleton Gillespie, Pablo Boczkowski, and Kirsten Foot. Cambridge, MA: The MIT Press, 2013. Print.
- Goguen, Joseph A. “Towards a Social, Ethical Theory of Information.” Social Science Research, Technical Systems and Cooperative Work: Beyond the Great Divide. Eds. Geoffrey Bowker, et al. Abingdon: Psychology Press, 1997. 27–56. Print.
- Goldstein, E. Bruce. “The Ecology of J. J. Gibson’s Perception.” Leonardo 14.3 (1981): 191–195. Print.
- González-Barahona, Jesús M. Personal Communication with Daniel German. 2008.
- Gross, Tom, Chris Stary, and Alex Totter. “User-Centred Awareness in Computer-Supported Cooperative Work-Systems: Structured Embedding of Findings From Social Sciences.” International Journal of Human-Computer Interaction 18.3 (2005): 323–360. Print.
- Grudin, Jonathan. “Computer-Supported Cooperative Work: History and Focus.” Computer 27.5 (1994): 19–26. Print.
- ———. “Why CSCW Applications Fail: Problems in the Design and Evaluation of Organizational Interfaces.” Proceedings of the 8th 2017 International Conference on Social Media 1988 ACM Conference on Computer-Supported Cooperative Work (CSCW ’88) (1988): 85–93. Print.
- Gutwin, Carl, and Saul Greenberg. “A Descriptive Framework of Workspace Awareness for Real-Time Groupware.” Computer Supported Cooperative Work 11.3–4 (2002): 411–446. Print.
- ———. “Design for Individuals, Design for Groups: Tradeoffs Between Power and Workspace Awareness.” Proceedings of the 8th 2017 International Conference on Social Media ACM CSCW 1998 Conference on Computer Supported Cooperative Work (CSCW ’98) (1998): 207–216. Print.
- ———. “Workspace Awareness for Groupware.” Proceedings of the 8th 2017 International Conference on Social Media ACM CHI 1996 Conference on Human Factors in Computing Systems (CHI ’96) (1996): 208–209. Print.
- Gutwin, Carl, Mark Roseman, and Saul Greenberg. A Usability Study of Awareness Widgets in a Shared Workspace Groupware System. Dept. of Computer Science, University of Calgary, 1996. Print.
- Gutwin, Carl, Saul Greenberg, and Mark Roseman. Workspace Awareness in Real-Time Distributed Groupware: Framework, Widgets, and Evaluation. Dept. of Computer Science, University of Calgary, 1998. Print.
- Harper, Gavin, and Jussi Kivilinna. Distributed Version Control in Open Source Software Development. University of Oulu, 2012. Print.
- Hassan, Robert. “Social Acceleration and the Network Effect: A Defence of Social Science Fiction and Network Determinism.” The British Journal of Sociology 61.2 (2010): 356–374. Print.
- Hayles, N. Katherine. “Print Is Flat, Code Is Deep: The Importance of Media-Specific Analysis.” Poetics Today 25.1 (2004): 67–90. Print.
- ———. “Virtual Bodies and Flickering Signifiers.” October 66 (1993): 69–91. Print.
- Heller, Brandon, Eli Marschner, Evan Rosenfeld, and Jeffrey Heer. “Visualizing Collaboration and Influence in the Open-Source Software Community.” Proceedings of the 8th 2017 International Conference on Social Media 8th Working Conference on Mining Software Repositories (MSR ’11) (2011): 223–226. Print.
- Hill, Benjamin Mako. “To Fork or Not To Fork: Lessons From Ubuntu and Debian” The Debian GNU/Linux Project. Canonical Ltd., 7 Aug. 2005. Web. 14 Apr. 2013. <http://mako.cc/writing/to_fork_or_not_to_fork.html>.
- Ito, Mizuko. Intimate Visual Co-Presence. Annenberg Center for Communication, University of Southern California, 2005. Print.
- Itoh, Kenji, ed. Handbook of Human Factors/Ergonomics. Tokyo: Asakura Publishing, 2003. Print.
- Kan, Stephen H. Metrics and Models in Software Quality Engineering. 2nd ed. Indianapolis: Addison-Wesley Professional, 2002. Print.
- Kelty, Christopher M. “Geeks and Recursive Publics.” Two Bits: The Cultural Significance of Free Software. Durham, London: Duke University Press, 2008. 27–63. Print.
- Klose, Simon, dir. TPB AFK: The Pirate Bay Away from Keyboard. Prod. Martin Persson. 8 Feb 2013. Documentary Film.
- Knappenberger, Brian, dir. We Are Legion: The Story of the Hacktivists. 2012. Documentary Film.
- Knuth, Donald E. “Computer Programming as An Art.” Communications of the ACM 17.12 (1974): 667–673. Print.
- Koc, Ali, and Abdullah Uz Tansel. “A Survey of Version Control Systems.” The 2nd International Conference on Engineering and Meta-Engineering (ICEME ’11), Orlando, Florida, USA, 2011. Print.
- Langlois, Ganaele. “Meaning, Semiotechnologies and Participatory Media.” Culture Machine 12 (2011): 1–27. Print.
- ———. “Participatory Culture and the New Governance of Communication.” Television & New Media 14.2 (2012): 91–105. Print.
- Langlois, Ganeaele, et al. “Mapping Commercial Web 2.0 Worlds: Towards a New Critical Ontogenesis.” The Fibreculture Journal 14 (2009): n. pag. Web. 5 May 2013. <http://fourteen.fibreculturejournal.org/fcj-095-mapping-commercial-web-2-0-worlds-towards-a-new-critical-ontogenesis/>.
- Leong, Susan, et al. “The Question Concerning (Internet) Time.” New Media & Society 11.8 (2010): 1267–1285. Print.
- Lessig, Lawrence. Code: Version 2.0. New York: Basic Books, 2006. Print.
- Licklider, Joseph C. R. “Man-Computer Symbiosis.” 1960. The New Media Reader. Eds. Noah Wardrip-Fruin and Nick Montfort. Cambridge, MA: The MIT Press, 2003. 74–82. Print.
- Loeliger, Jon. Version Control with Git. Sebastopol: O’Reilly Media, Inc., 2009. Print.
- Lovink, Geert. Networks Without a Cause: A Critique of Social Media. Cambridge: Polity, 2012. Print.
- Lv, Qin, et al. “Search and Replication in Unstructured Peer-to-Peer Networks.” Proceedings of the 8th 2017 International Conference on Social Media 16th international conference on Supercomputing (ICS ’02) (2002): 84–95. Print.
- Mackenzie, Adrian. “More Parts Than Elements.” Society and Space 30.2 (2010): 335–350. Print.
- ———. Transductions: Bodies and Machines at Speed. London: Continuum Press, 2002. Print.
- Maeda, John. Creative Code: Aesthetics + Computation. London: Thames & Hudson, 2004. Print.
- Manovich, Lev. “Inside Photoshop.” Computational Culture 1 (2011): n. pag. Web. 7 Feb. 2013. <http://computationalculture.net/article/inside-photoshop>.
- ———. “The Practice of Everyday (Media) Life.” Critical Inquiry 35.2 (2009): 319–331. Print.
- Marx, Gary T. “A Tack in the Shoe: Neutralizing and Resisting the New Surveillance.” Journal of Social Issues 59.2 (2003): 369–390. Print.
- McGrenere, Joanna, and Wayne Ho. “Affordances: Clarifying and Evolving a Concept.” Proceedings of Graphics Interface 2000 (2000): 1–8. Print.
- Milenkovic, Milan, et al. “Toward Internet Distributed Computing.” Computer 38.5 (2003): 38–46. Print.
- Mockus, Audris. Amassing and Indexing a Large Sample of Version Control Systems: Towards the Census of Public Source Code History. Avaya Labs Research, 2009. Print.
- Moen, Rick. “Fear of Forking.” Linuxmafia. Rick Moen, 14 Nov. 1999. Web. 14 Apr. 2013. <http://linuxmafia.com/faq/Licensing_and_Law/forking.html>.
- Moran, Albert. “Global Franchising, Local Customizing: The Cultural Economy of TV Program Formats.” Continuum: Journal of Media & Cultural Studies 23.2 (2009): 115–125. Print.
- Morris, James H. “Software Product Management and the Endless Beta.” jimmorris.blogspot.nl. Carnegie Mellon University, 30 Aug. 2006. Web. 5 May 2013. <http://jimmorris.blogspot.nl/2006_08_01_jimmorris_archive.html
- Mortimer, Ian. “Beyond The Facts.” The Times Literary Supplement (TLS) 26 Sept. 2008: 16–17. Print.
- Murdoch, Graham. “Thin Descriptions: Questions of Method in Cultural Analysis.” Cultural Methodologies. Ed. Jim McGuigan. London: Sage, 1997. 91–98. Print.
- Murthy, Dhiraj. “Digital Ethnography: An Examination of the Use of New Technologies for Social Research.” Sociology 42.5 (2008): 837–855. Print.
- Negroponte, Nicholas. “From Soft Architecture Machines.” The New Media Reader. Eds. Noah Wardrip-Fruin and Nick Montfort. Cambridge, MA: The MIT Press, 2003. 354–366. Print.
- Nelson, Theodor H. “A File Structure for the Complex, the Changing, and the Indeterminate.” The New Media Reader. Eds. Noah Wardrip-Fruin and Nick Montfort. Cambridge, MA: The MIT Press, 2003. 134–146. Print.
- Niederer, Sabine, and José F. T. M. van Dijck. “Wisdom of the Crowd or Technicity of Content? Wikipedia as a Sociotechnical System.” New Media & Society 12.8 (2010): 1368–1387. Print.
- Norman, Donald A. “Affordance, Conventions, and Design.” Interactions 6.3 (1999): 38–43. Print.
- Oosterhuis, Kas, et al., eds. “protoSPACE.” Hyperbody: First Decade of Interactive Architecture. Eds. Kas Oosterhuis, et al. Heijningen: Jap Sam Books, 2012. 500–563. Print.
- O’Reilly, Tim. “What Is Web 2.0: Design Patterns and Business Models for the Next Generation of Software.” O’Reilly. O’Reilly Media, Inc., 30 Sept. 2005. Web. 27 Nov. 2012. <http://oreilly.com/web2/archive/what-is-web-20.html>.
- Pagel, Mark. “How language transformed humanity.” TEDGlobal. Long Beach, California, USA. July 2011. Conference Presentation. <http://www.ted.com/talks/mark_pagel_how_language_transformed_humanity.html>.
- Parikka, Jussi. “Archives in Media Theory: Material Media Archeology and Digital Humanities.” Understanding Digital Humanities. Ed. David M. Berry. Basingstoke: Palgrave Macmillan, 2012. 85–104. Print.
- Pearson, Matt. “Why Artwork Should Be Open Sourced and Revisited.” The Creators Project. Intel/VICE, 1 Mar. 2013. Web. 1 Mar. 2013. <http://www.thecreatorsproject.com/blog/why-artwork-should-be-open-sourced-and-revisited>.
- Pinelle, David, Carl Gutwin, and Saul Greenberg. “Task Analysis for Groupware Usability Evaluation: Modeling Shared-Workspace Tasks with the Mechanics of Collaboration.” ACM Transactions on Computer-Human Interaction (TOCHI) 10.4 (2003): 281–311. Print.
- Poell, Thomas, and Kaouthar Darmoni. “Twitter as a Multilingual Space: The Articulation of the Tunisian Revolution Through #Sidibouzid.” NECSUS European Journal of Media Studies 1 (2012): n. pag. Web. 18 Feb. 2013. <http://www.necsus-ejms.org/twitter-as-a-multilingual-space-the-articulation-of-the-tunisian-revolution-through-sidibouzid-by-thomas-poell-and-kaouthar-darmoni/>.
- Raymond, Eric S. “The Cathedral and the Bazaar.” First Monday. 3.2 (1998): n. pag. Web. 29 Mar. 2013. <http://www.firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/578/499>.
- Redmiles, David, et al. “Continuous Coordination: A New Paradigm to Support Globally Distributed Software Development Projects.” Wirtschaftsinformatik 49 (2007): 28–38. Print.
- Redmond, Timothy, et al. Managing Change: An Ontology Version Control System. Clark & Parsia, LLC, Stanford University, University of Manchester, 2008. Print.
- Rieder, Bernhard. “What Is in PageRank? A Historical and Conceptual Investigation of a Recursive Status Index.” Computational Culture 2 (2013): n. pag. Web. 14 Apr. 2013. <http://computationalculture.net/article/what_is_in_pagerank>.
- Rieder, Bernhard, and Theo Röhle. “Digital Methods: Five Challanges.” Understanding Digital Humanities. Ed. David M. Berry. Basingstoke: Palgrave Macmillan, 2012. 67–84. Print.
- Rienhard, Walter, et al. “CSCW Tools: Concepts and Architectures.” Computer 27.5 (1994): 28–36. Print.
- Rigby, Peter C., et al. Collaboration and Governance with Distributed Version Control. University of Victoria/University of California, 2010. Print.
- Ringle, Eddie. “How to Use GitHub to Contribute to Open Source Projects.” LockerGnome. Lockergnome, Inc., 13 Dec. 2011. Web. 7 Mar. 2013. <http://www.lockergnome.com/web/2011/12/13/how-to-use-github-to-contribute-to-open-source-design/>.
- Ripeanu, Matei. Peer-to-Peer Architecture Case Study: Gnutella Network. Dept. of Computer Science, The University of Chicago, 2001. Print.
- Rogers, Everett M. Diffusion of Innovation. 3th ed. Glencoe: Free Press, 1962. Print.
- Rogers, Richard A. The End of the Virtual: Digital Methods. Amsterdam: Vossiuspers UvA, 2009. Print.
- ———. Digital Methods. Cambridge, MA: The MIT Press, forthcoming. Print.
- Røssaak, Eivind. “The Archive in Motion: An Introduction.” The Archive in Motion: New Conceptions of the Archive in Contemporary Thought and New Media Practices. Ed. Eivind Røssaak. Oslo: Studies from the National Library of Norway, 2011. 11–26. Print.
- Şahin, Erol, et al. “To Afford or Not to Afford: A New Formalization of Affordances Toward Affordance-Based Robot Control.” Adaptive Behavior 15.4 (2007): 447–472. Print.
- Şahin, Erol. State-of-the-Art and Formalization for Robotics. KOVAN Research Lab/Dept. of Computer Engineering, Middle East Technical University, 2008. Lecture.
- Sarma, Anita, and André van der Hoek. Visualizing Parallel Workspace Activities. Institute of Software Research, University of California, 2003. Print.
- Sarma, Anita, David Redmiles, and André van der Hoek. “Empirical Evidence of the Benefits of Workspace Awareness in Software Configuration Management.” Proceedings of the 8th 2017 International Conference on Social Media 16th International Symposium on Foundations of Software Engineering (FSE 16) (2008): 113–123. Print.
- Sarma, Anita, et al. “Tesseract: Interactive Visual Exploration of Socio-Technical Relationships in Software Development.” 31st International Conference on Software Engineering (ICSE ‘09) (2009): 23–33. Print.
- Sarma, Anita, Zahra Noroozi, and André van der Hoek. “Palantír: Raising Awareness Among Configuration Management Workspaces.” Proceedings of the 8th 2017 International Conference on Social Media 25th International Conference on Software Engineering (ICSE ‘03) (2003): 444–454. Print.
- Schmidt, Kjeld, and Carla Simone. “Coordination Mechanisms: Towards a Conceptual Foundation of CSCW Systems Design.” Computer Supported Cooperative Work (CSCW) 5.2–3 (1996): 155–200. Print.
- Schmidt, Kjeld, and Liam Bannon. “Taking CSCW Seriously: Supporting Articulation Work.” Computer Supported Cooperative Work (CSCW) 1.1 (1992): 7–40. Print.
- Schmidt, Kjeld. “The Problem with ‘Awareness’: Introductory Remarks on Awareness in CSCW.” Computer Supported Cooperative Work (CSCW) 11.3 (2002): 285–298. Print.
- Sink, Eric. Version Control by Example. Champaign: Pyrenean Gold Press, 2011. Print.
- Slater, Don, and Daniel Miller. The Internet: An Ethnographic Approach. Oxford: Berg, 2000. Print.
- Suchman, Lucy A. “Do Categories Have Politics?” Computer Supported Cooperative Work (CSCW) 2 (1993): 177–190. Print.
- ———. Plans and Situated Actions: The Problem of Human-Machine Communication. Palo Alto: Xerox Corporation, 1985. Print.
- Stallman, Richard. “The GNU Manifesto.” GNU Project. Free Software Foundation, Inc., 1985. Web. 15 Mar. 2013. <http://www.gnu.org/gnu/manifesto.html>.
- ———. “The GNU Operating System and the Free Software Movement.” Open Sources: Voices From the Open Source Revolution. Eds. Chris DiBona, Sam Ockman, and Mark Stone. Sebastopol: O’Reilly Media, Inc., 1999. 53–70. Print.
- Stokic, Dragan, Ana Teresa Correia, and Philip Reimer. “Social Computing Solutions for Collaborative Learning and Knowledge Building Activities in Extended Organization.” Proceedings of the 8th 2017 International Conference on Social Media 5th International Conference on Mobile, Hybrid, and On-line Learning (eLmL ’13) (2013): 24–29. Print.
- Tanenbaum, Andrew S., and Maarten van Steen. Distributed Systems: Principles and Paradigms. 2nd ed. Upper Saddle River: Prentice Hall, 2007. Print.
- Vaughan-Nichols, Steven J. “Android and Linux re-merge into one operating system.” ZDNet. CBS Interactive, 19 Mar. 2012. Web. 8 Apr. 2013. <http://www.zdnet.com/blog/open-source/android-and-linux-re-merge-into-one-operating-system/10625>.
- Viégas, Fernanda B., Martin Wattenberg, and Kushal Dave. “Studying Cooperation and Conflict Between Authors with History Flow Visualizations.” Proceedings of the 8th 2017 International Conference on Social Media SIGCHI Conference on Human Factors in Computing Systems (CHI ’04) (2004): 575–582. Print.
- Virilio, Paul. The Information Bomb. London: Verso, 2000. Print.
- Viseur, Robert. “Forks Impact and Motivations in Free and Open Source Projects.” International Journal of Advanced Computer Science and Applications (IJACSA) 3.2 (2012): 117–112. Print.
- Vitali, Stefania, James B. Glattfelder, and Stefano Battiston. “The Network of Global Corporate Control.” PLoS ONE 6.10 (2011): e25995. Print.
- Weber, Nicholas M. “Combined Methods, Thick Descriptions: Languages of Collaboration on Github.” Proceedings of the 8th 2017 International Conference on Social Media American Society for Information Science and Technology 49.1 (2013): 1–4. Print.
- Weltevrede, Esther, and Anne Helmond. “Where Do Bloggers Blog? Platform Transitions Within the Historical Dutch Blogosphere.” First Monday 17.2 (2012): n. pag. Web. 19 Feb. 2013. <http://firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/3775/3142>.
- Wiener, Norbert. Cybernetics, or Communication and Control in the Animal and the Machine. 1948. 2nd ed. Cambridge, MA: The MIT Press, 1961. Print.
- Wilson, Rob, and Wimal Dissanayake. “Introduction: Tracking the Global/Local (Excerpts).” Global/Local: Cultural Production and the Transnational Imaginary. Eds. Rob Wilson and Wimal Dissanayake. Durham/London: Duke University Press, 1996. 1–8. Print. Asia-Pacific: Culture, Politics, and Society.
- Winograd, Terry, and Fernando Flores. Understanding Computers and Cognition: A New Foundation for Design. Norwood: Ablex Publishing, 1986. Print.
- Wood, Jessica A. “The Darknet: A Digital Copyright Revolution.” Richmond Journal of Law & Technology 16.4 (2010): 1–60. Print.
- Yip, Alexander, Benjie Chen, and Robert Morris. “Pastwatch: A Distributed Version Control System.” 3rd Symposium on Networked Systems Design and Implementation (NSDI ‘06), San Jose, California, 2006. Print.
11. Appendix